lab06
- lab06的内容是用logisim来比较pipelined和single cycle的区别,主要区别就是adder和mul是否分开,只要理解了setup_time,hold_time, clk-to-q delay等概念 就可以了。
Binary prefix
- 在计算机中,我们常常遇到一些单位,比如KB、MB、GB等,这些单位在不同的上下文中可能有不同的含义。比如1kB究竟是1000B还是1024B呢?在硬盘空间和网络传输中,一般来说都是1000倍,而其他的cache、内存等都是1024倍。为了避免混淆,国际电工委员会(IEC)引入了二进制前缀,比如kibi,mebi,gibi等(Ki,Mi,Gi,Ti).
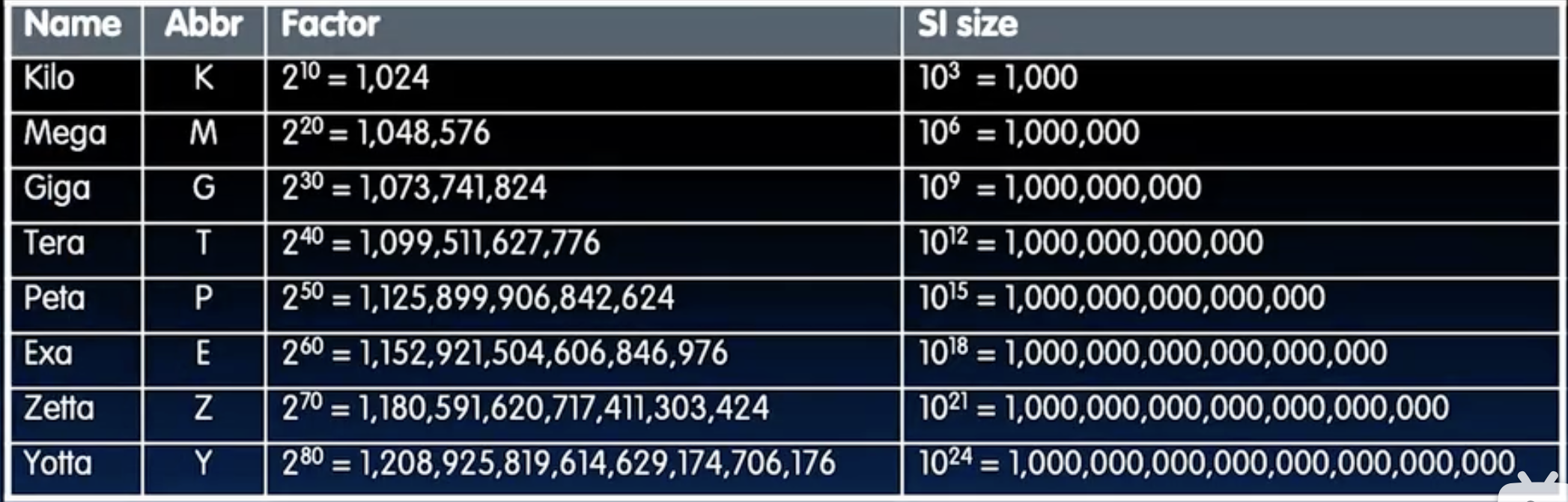
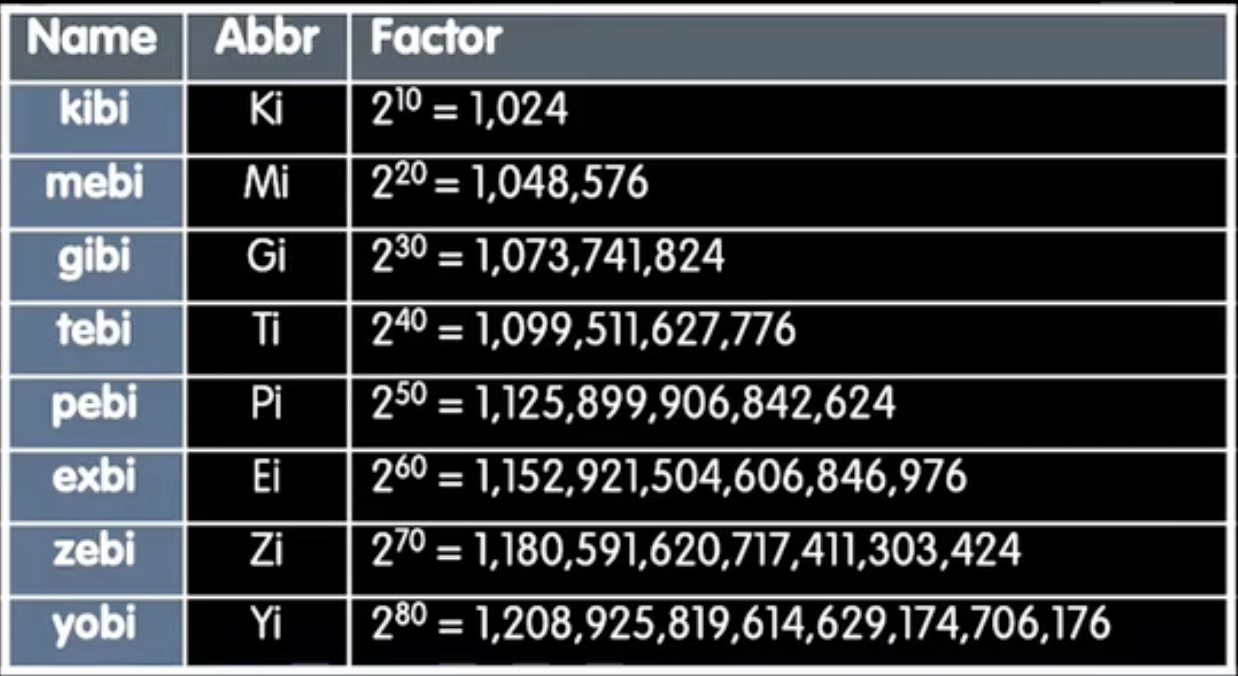
- 这些似乎很难记,ezy or eyz ? 可爱的dan老师在几年前已经和学生们想出了很多口诀,比如:Kissing me gives ten percent extra zeal & youth! 真的是天才老师啊。
- 下面是一个快速对应表:

| |
Background
- 我们理想中的内存是一个像register快,和硬盘一样大的东西🤣,但显然做不到。
- 1980年代,访存(DRAM)速度和CPU速度几乎一样,所以直接取内存没什么影响,但是从1980到2004左右,cpu的频率以几乎55%的速度上涨,而DRAM的速度只有7%
- 导致cpu几乎比DRAM快了1000倍,如果去内存取个东西,cpu要空等1000个周期!!不可饶恕。
Memory Caching
- 奇妙比喻:当你在图书馆写报告时,你会拿一堆和报告有关的书放在你的桌子上,这些书往往都是有用的,你不用来来回回去找书架上的书了。
- Cache is a copy of a subset of main memory.
| Register | Cache | DRAM | |
|---|---|---|---|
| Speed | Fastest | Fast | Slow |
| Size | Small | Medium | Large |
| Cost | Expensive | Moderate | Cheap |
How is the Hierarchy Managed ?
- register <-> memory : 由编译器管理,编译器会把一些频繁使用的变量放在寄存器里,这样访问速度更快。或者是手动汇编编程,直接用寄存器来存储数据。
- cache <-> memory : By the cache controller hardward.
- main memory <-> disks(Secondary storage)
- By the operating system (virtual memory)
- Virtual to physical address mapping assisted by the hardware (‘Translation lookaside buffer’ TLB🤣)
Direct-Mapped Cache
- Direct-mapped cache是最简答的一种cache设计,内存地址被分成三部分:tag, index, offset。index用来定位cache中的行,offset用来定位行内的字节,tag用来验证cache行是否包含所需的数据。Dan老师又想出了一种绝妙的记忆方法,在spanish中,tio = 叔叔,tio dan 🤣
- 似乎比较简单,省略…
- 唯一需要注意的是在程序刚刚初始化的时候,cache里肯定是有东西的,如果直接按照上面的规则,有可能还真能命中,但实际上这些都是garbage,所以需要设置一个valid bit来标记cache行是否有效。
- 设想如果我们能将cache做的和内存一样大,那么使用直接映射就太妙了,每个内存块都有自己独属的缓存位置,当然这只是想想。
Fully-Mapped Cache
- 首先指出直接映射的优势,对于内存块中的任何一个和缓存等宽的部分,我们可以直接计算出它在缓存中的位置,这样我们不需要遍历缓存,直接计算位置,然后看对应的位置的tag是否符合即可。这种方式非常的便利,缺点是对于一批同样缓存位置的内存地址块,它们会出现内存抖动的现象,导致利用率在某些特殊情况非常之低。
- 为了解决这种情况,我们可以使用完全映射的cache设计,完全映射的cache没有index,所有的内存地址都可以放在cache中的任何一个空位,在缓存充满之前,不会出现内存抖动的情况,在缓存充满后也只需要解决替换哪一个的问题(一般用least recently used - LRU的策略),但是完全映射的cache需要遍历整个cache来寻找数据,效率非常低,所以完全映射的cache一般只用在小容量的cache中,比如TLB。
Set-Associative Cache
- 组相连映射cache介于两者之间,为了避免直接映射的内存抖动问题,并且提高完全映射的效率,我们可以在直接映射中的一个index内增加几个位置,使得相同类的内存映射后可以并存在这个index内的不同位置,减少缓存抖动的情况。
- way的数量就是一个set内部的block的数量。
- Basic Idea:
- cache is direct-mapped respect to sets.
- each set is fully associative with N blocks in it.
- It is Direct-Mapped if it’s 1-way set associative.
- It is Fully Assoc if its’ M-way set assoc for a cache with M blocks.
- 一个 4-way set associative cache的例子:
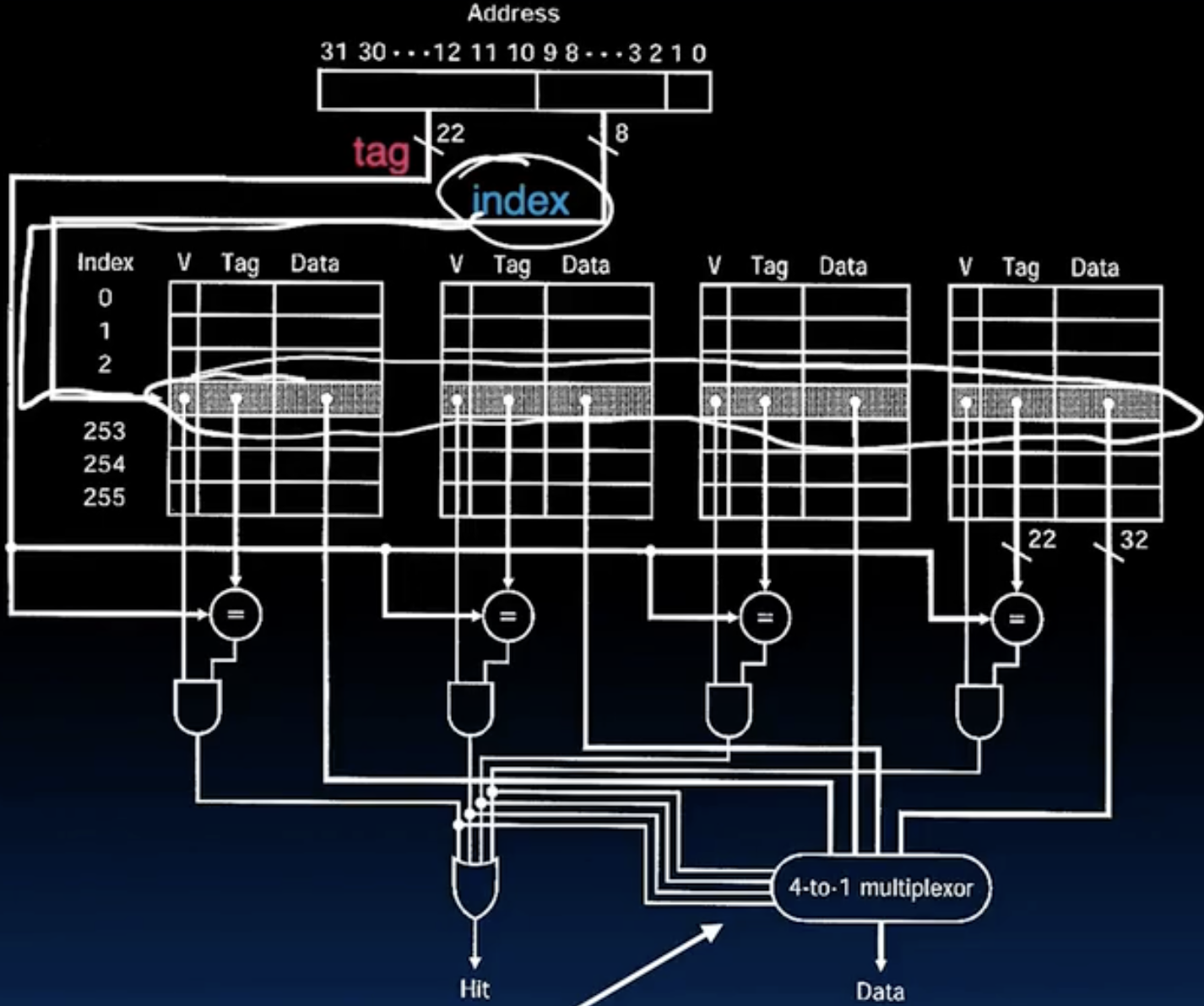
- 可以印证前面对fully-mapped的分析,在组内由于需要判断tag,需要使用大量的比较器,所以效率低。4个判断信号决定了最终选择的data,但是图中似乎忘了offset的选择(
Block Replacement Policy
- LRU: Least Recently Used, 替换掉最近最久未使用的block。
- FIFO: First In First Out, 替换掉最早进入cache的block。
- Random: 随机替换一个block。
- 课程中提供的那个模拟缓存网站似乎打不开了,我搜到了同一个作者的另一个网站, 可以设置block数量,set数量,并随机生成内存访问顺序来实时观测miss rate,hit rate。
| |
Average Memory Access Time (AMAT)
- Minimize : Average Memory Access Time = Hit Time + Miss Rate * Miss Penalty
| |
How to reduce Miss Penalty ?
- 通过增加block的大小,我们每次加载更大的block,可以有效降低miss rate, 但是block变大了会增加 每次取、扔数据的时间,所以blocksize不能太大。简单的说就是更大的缓存。
- 设计多级缓存!一个很妙的比喻,当你在钢丝绳上行走时,下面有一个小小的安全网,我们可以在下面再加一个更大的安全网,这样即便是掉下了第一个安全网,我们还有第二个安全网来保护我们,这就是多级缓存的思想,一级缓存速度快但容量小,二级缓存速度较慢但容量大,这样可以有效降低miss penalty。多层结构无疑是计算机科学中一个非常经典的设计模式了。
Multi-level cache hierarchy:
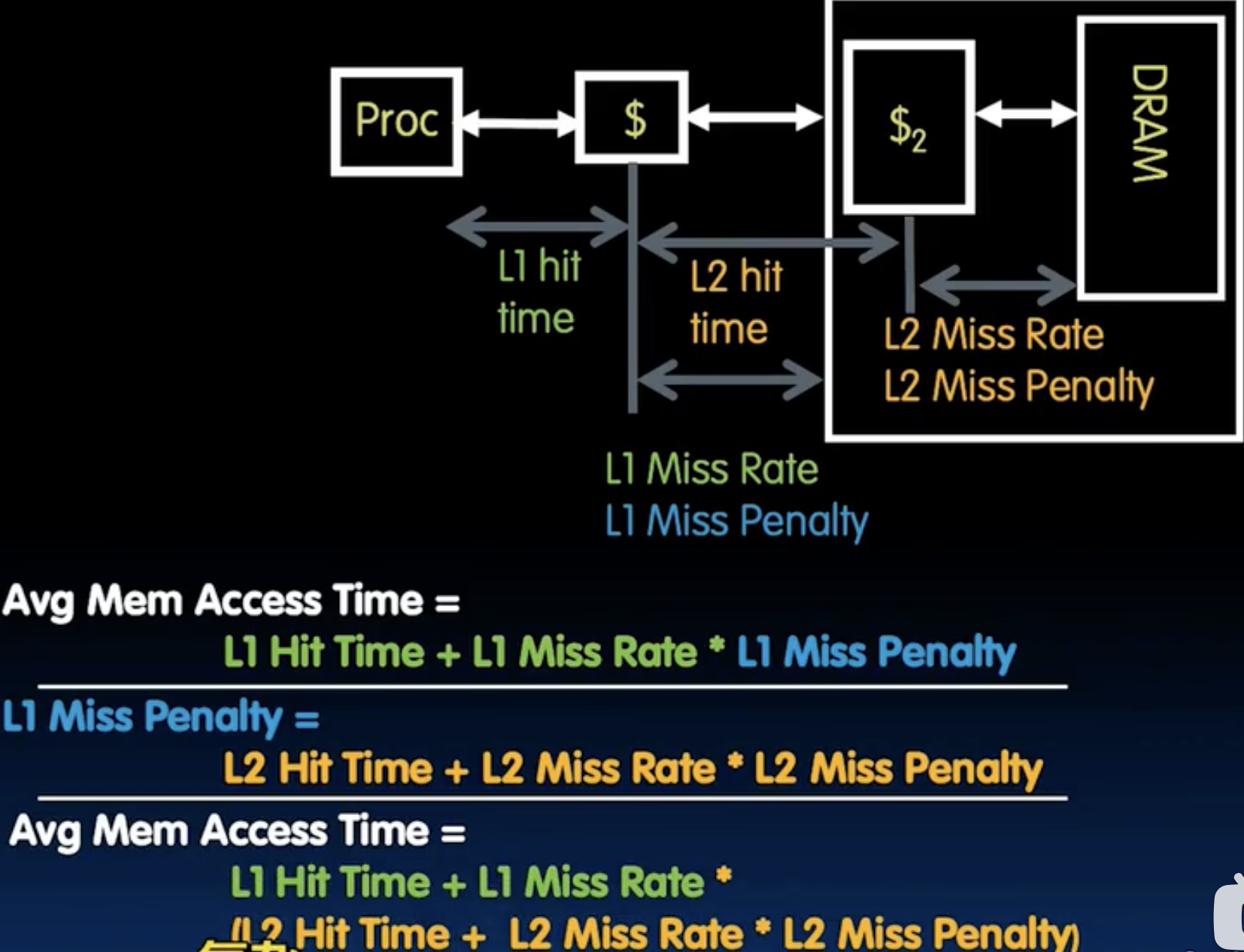
- 有点像递归,在早期mac电脑中搭配的Intel i7 processor就有三级cache,L1 cache是每一个core独享的(而且就在处理器内部),64KB, L2 cache是每一个core独享的,(不在处理器内部?),512KB,L3 cache是所有core共享的,8MB。
| |