Page Tables
Size of Page Tables
- E.g., 32-Bit virtual address, 4-KiB pages: (from VPN to PPN的一个映射)
- Single page table size = $2^{20} \times 4$ Bytes = 4-MiB. 如果你的电脑是4GB内存的,这仅仅占用了0.1%,完全可以接受。
- Total size for 256 processes (each needs a page table) = 1-GiB (总内存的25%),这这这就有点太大了。
- 甚至,现在大多数电脑的操作系统是64位的,那么别玩了,直接爆了。
How to small down Page Tables size?
- 一个直觉的想法是page table之所以大是因为它的VPN和PPN太多了,所以我们提高page size,来减小VPN和PPN的大小,比如我们使用8-KiB的页,那么VPN和PPN的位数就会减少1位,page table的大小就会减半了(按道理来说一个entry不用32了,应该是31,但是姑且默认是4字节吧)。但是这个会导致内存碎片问题,即一个程序可能占用了一个8-KiB的页,但是它实际只使用了4-KiB的空间,剩下的4-KiB就浪费了。分的越大,碎片问题越严重。
- 另一中想法是分层page table,即Split PT in two (or more) parts, which is done in RISC-V.
Hierarchical Page Table
- 如下图所示,以两层page table为例,我们可以将20位的VPN分成两部分p1和p2,每部分是10位。我们首先有一个root of the current page table, 这个东西一般在RISC-V中是用一个特殊的寄存器来存的(SPTBR),它指向了Level 1 page table的base address,其中,每一个entry都是4字节的,都存储了一堆信号位和一个Level 2 Page Table的base address(这个address是physical的),我们通过第一个10位p1来从下往上选择对应的entry,同理p2用来在Level 2 page table中的选择对应的entry。
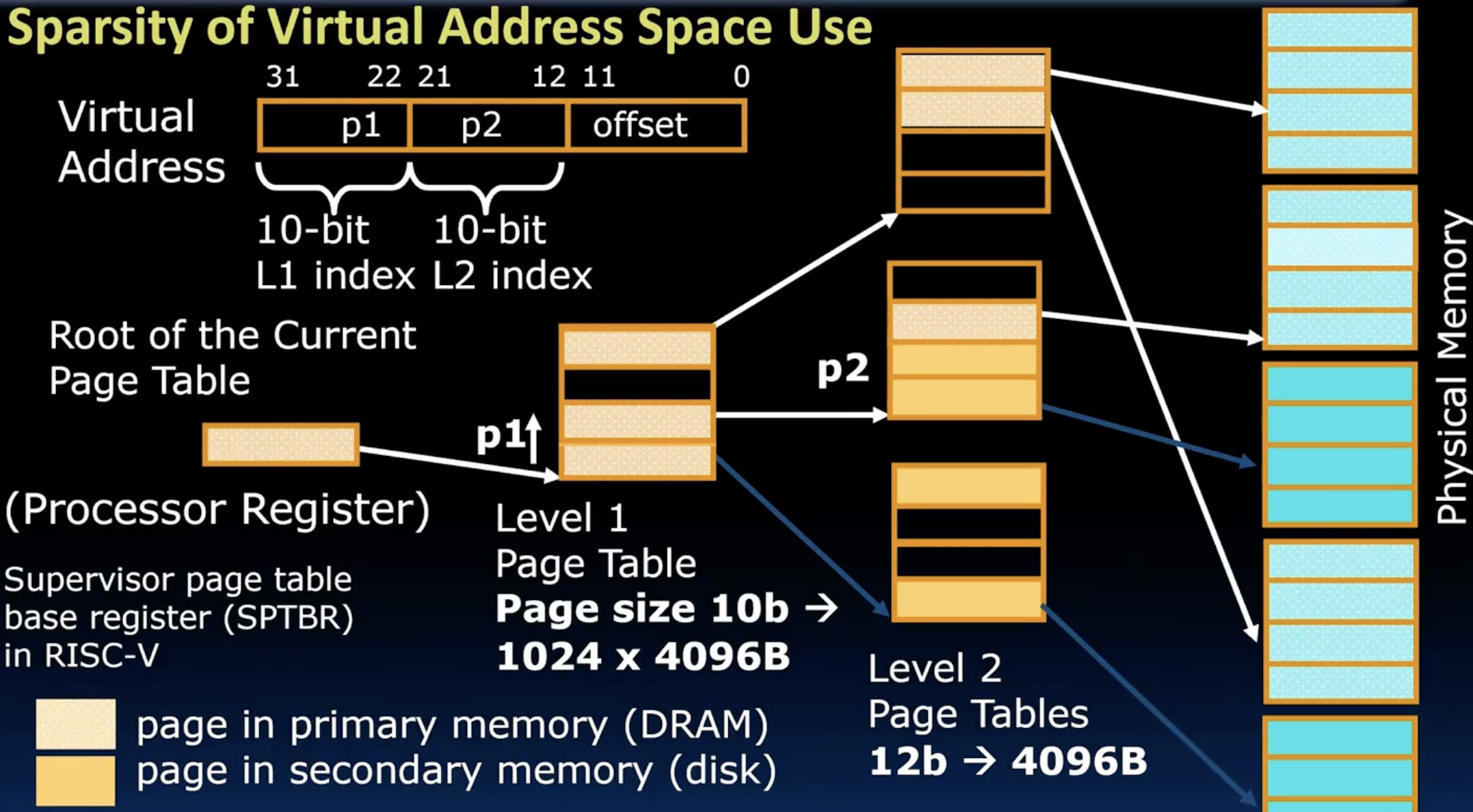
当进程切换时,操作系统会保存当前进程的SPTBR寄存器的值,并且加载新进程的SPTBR寄存器的值,这样就完成了page table的切换。在上述的2 level 页表设计下,我们似乎一共使用了1024 * 4B + 1024 * 1024 * 4B = 4-KiB + 4-MiB = 4.004-MiB的内存来存储一个进程的page table ? 你可能会疑惑,怎么占用还变多了,这里不得不提到一个重要的概念:sparse page table,即稀疏页表,我们上面的计算中是假设level 2的所有页表都被使用了,但是实际上并不是如此,比如一个程序,我们有.data,.text,stack,heap等,其中stack和heap是动态的,有大量的未使用区域,如果我们不使用2-level page table,那么我们需要一个完整的32位VPN的page table(4MiB)来存储,但是如果使用2-level page table,那么我们可能只用到了level 2 [0],[1],[2], [100],[101],[300],中间大量的未使用level 2 page table就不需要分配了,这样就大大节省了内存空间,十分灵活。
在32位最后的page table entry中的低10位是一堆信号位,比如R,W,X…,高22位则是真正的PPN。如果是64位操作系统,则通常使用4 level的page table。
Translation Lookaside Buffers
如果我们把所有level的page table都放到内存中,那么对于1 level的page table,我们需要首先访问内存得到PPN,然后根据PPN再次访问内存,总计两次访问内存。对于2 level的page table,我们需要访存3次,对于现代64位的4 level page table,我们需要访存5次,这样的效率是非常低的,毕竟访问一次内存的时间相当于是CPU周期的1000倍,太久太久。
- 于是,有先贤提出了Translation Lookaside Buffers(TLB), 它就是一个小cache,那为什么名字里是buffers呢?还记得我们在上一讲中提到VM的出现早于cache(由于当时的CPU周期和内存访问时间差不多),而TLB作为VM的一个优化硬件自然同时期被提出,所以它比cache早,第一个设计它的人不知道cache的概念,于是就叫它Buffers了。
- 它的工作原理如下图所示:
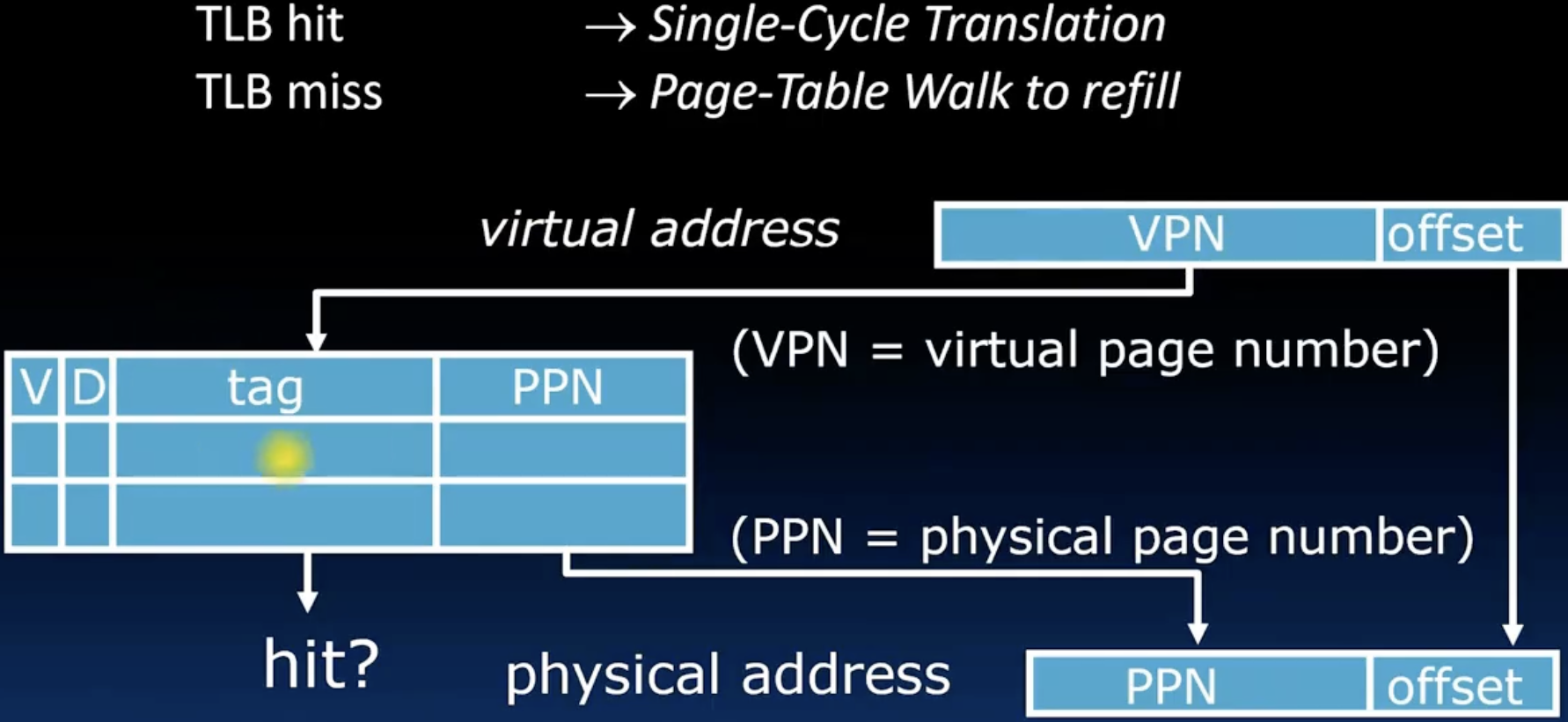
这里对Dirty bit的解释有些绕口,首先我们要理解什么时候要swap,在上一讲中我们知道,当DRAM爆满并且有新的进程需要allocate 一个物理页的时候会发生swap,如果那个被swap的物理页的Dirty bit是0,那么直接swap即可;如果是1,那么我们需要更新它在磁盘中的那个"原件"(当然它必须是文件页,而不是那种临时分配的匿名页),然后swap。 Valid bit真代表这个页面是否在DRAM中吗,由后面的一些思考,或许代表该条entry是否有效更合适。
TLB Designs
- Typcally 32-128 entries, usually fully associative.
- Each entry maps a large page, hence less spatial locality across pages -> more likely that two entries conflict.
- Sometimes larger TLBs(256-512 entries) are 4-8 way set associative.
- Larger systems sometimes have multi-level(L1 and L2) TLBs.
- Random or FIFO replacement policy.
- “TLB Reach”: Size of largest virtual address space that can be simultaneously mapped by TLB.
| |
Where Are TLBs Located?
- Which should we check first: Cache or TLB?
- 当然是TLB啦,我们在程序中使用的任何地址都是虚拟地址,所以必须先通过TLB来转换成物理地址,然后再去cache中访问数据。
- 故缓存中都是PA(Physical Address).
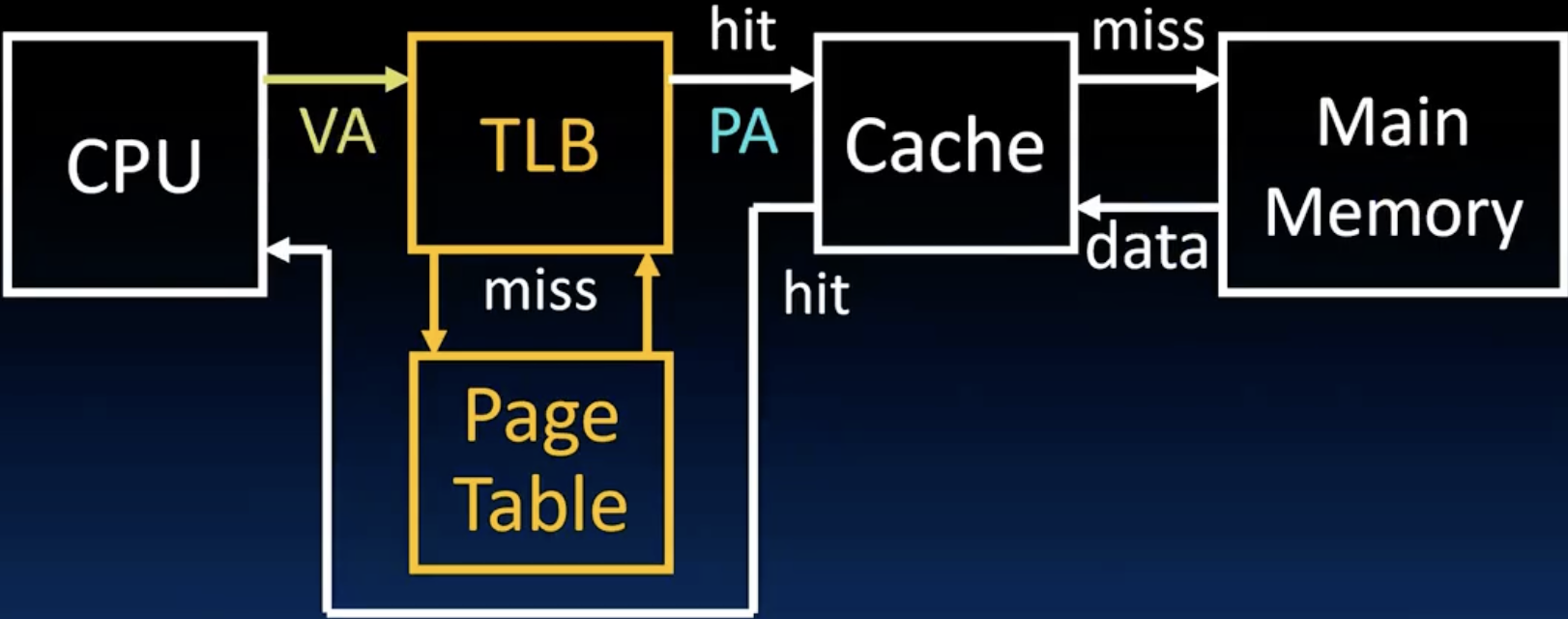
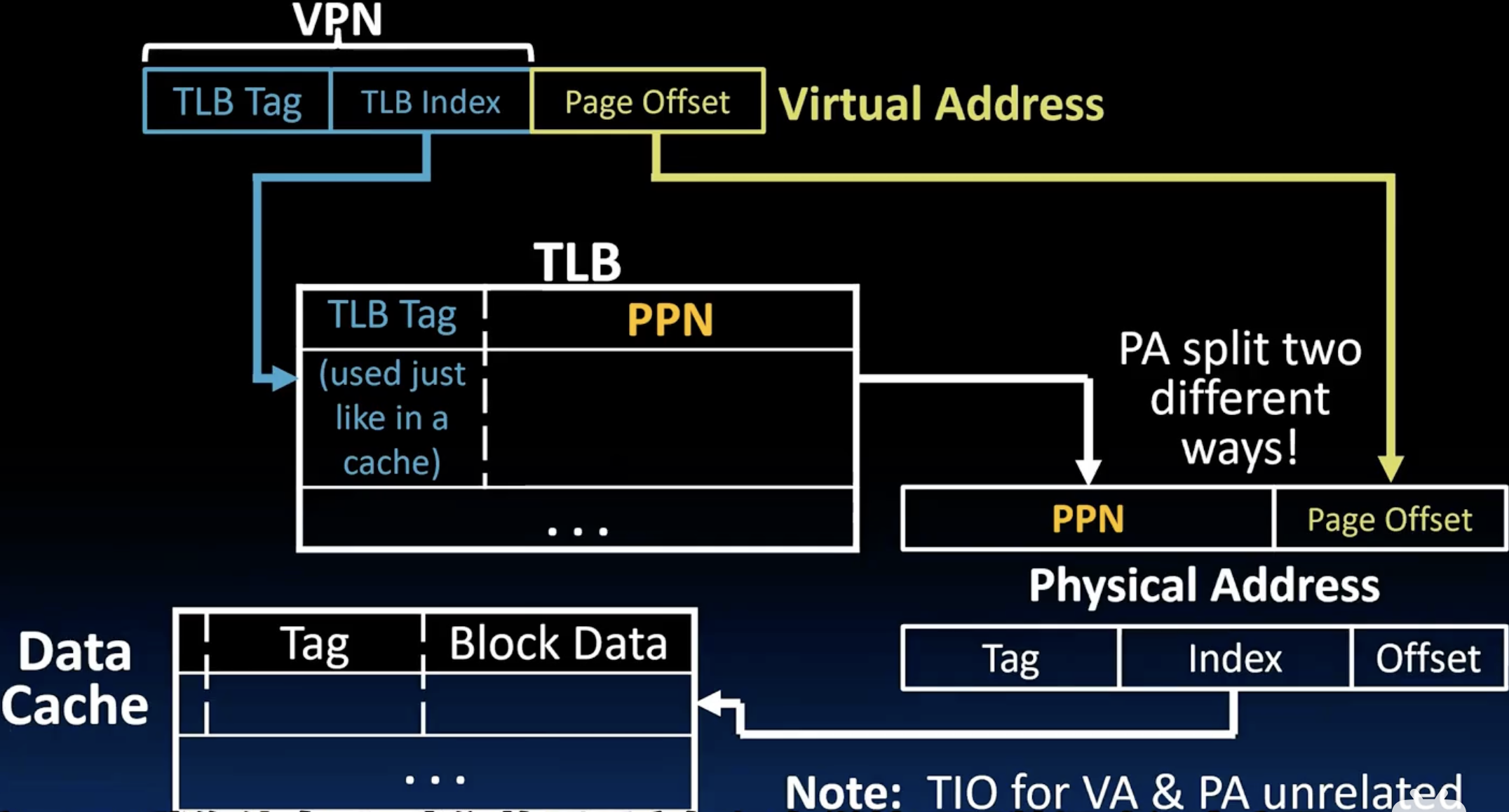
- 如上图所示,TLB在CPU和Cache之间,现代工艺下TLB的命中率能达到99.9999%,这一点符合我们之前提到的TLB miss的损失巨大问题。如下图所示,一个完整的VA到PA的过程,需要注意的是在得到了完整的PA之后,如果下一步是访问cache,那么我们就需要重新将PA分成tag、index和offset,这个完全取决于cache的规格,和页的大小无关。
TLBs in Datapath
- 在理解了TLB的工作原理和位置之后,我们可以尝试将它添加到之前提到的CPU datapath中,如下图所示,CPU中有两个小cache,在进入它们之前都需要过一个TLB来进行地址转换。
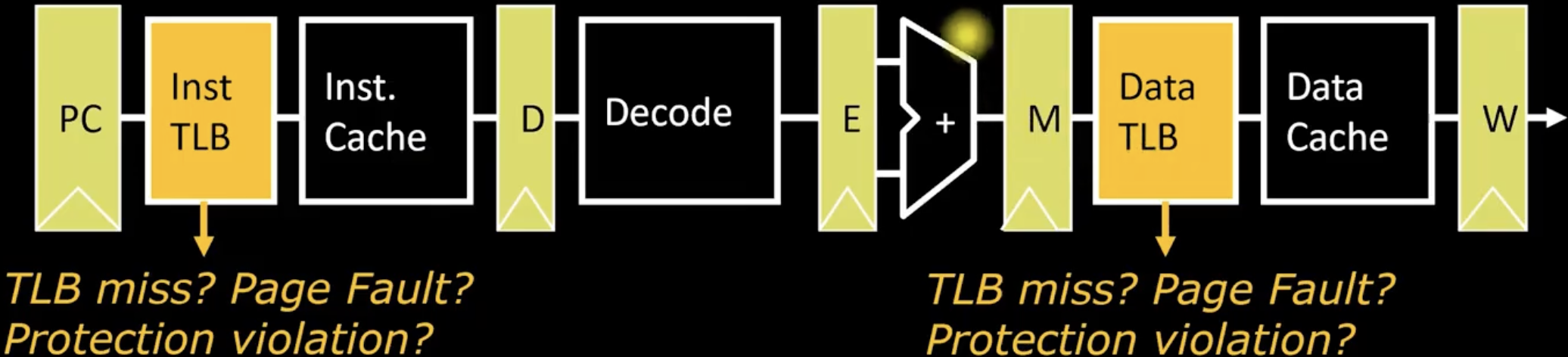
- 需要注意的事,我们的datapath设计需要考虑到各种异常的情况,比如TLB miss,page fault等等。
- Handling a TLB miss needs a hardware or software mechanism to refill TLB, which usually done in hardware,可能是一个比较复杂的状态机?
- Handling a page fault (e.g., page is on disk) needs a precise trap so software handler can easily resume after retrieving page.
- Protection violation may abort process. 这类异常通常是由于访问某个内存地址却没有对应权限引起的,比如一个用户试图访问内核空间。
- 如下图所示,当遇到TLB miss时,会发送一个信号到Hardware Page Table Walker, 它会根据当前活跃程序的Page-Table Base Register来访问内存中的page table来找到对应的PPN,然后将这个PPN写回TLB中,然后去访问cache。如果遇到page fault或者是protection violatioin,那么会向OS发送一个trap,OS会接管当前的进程,来处理这个异常。
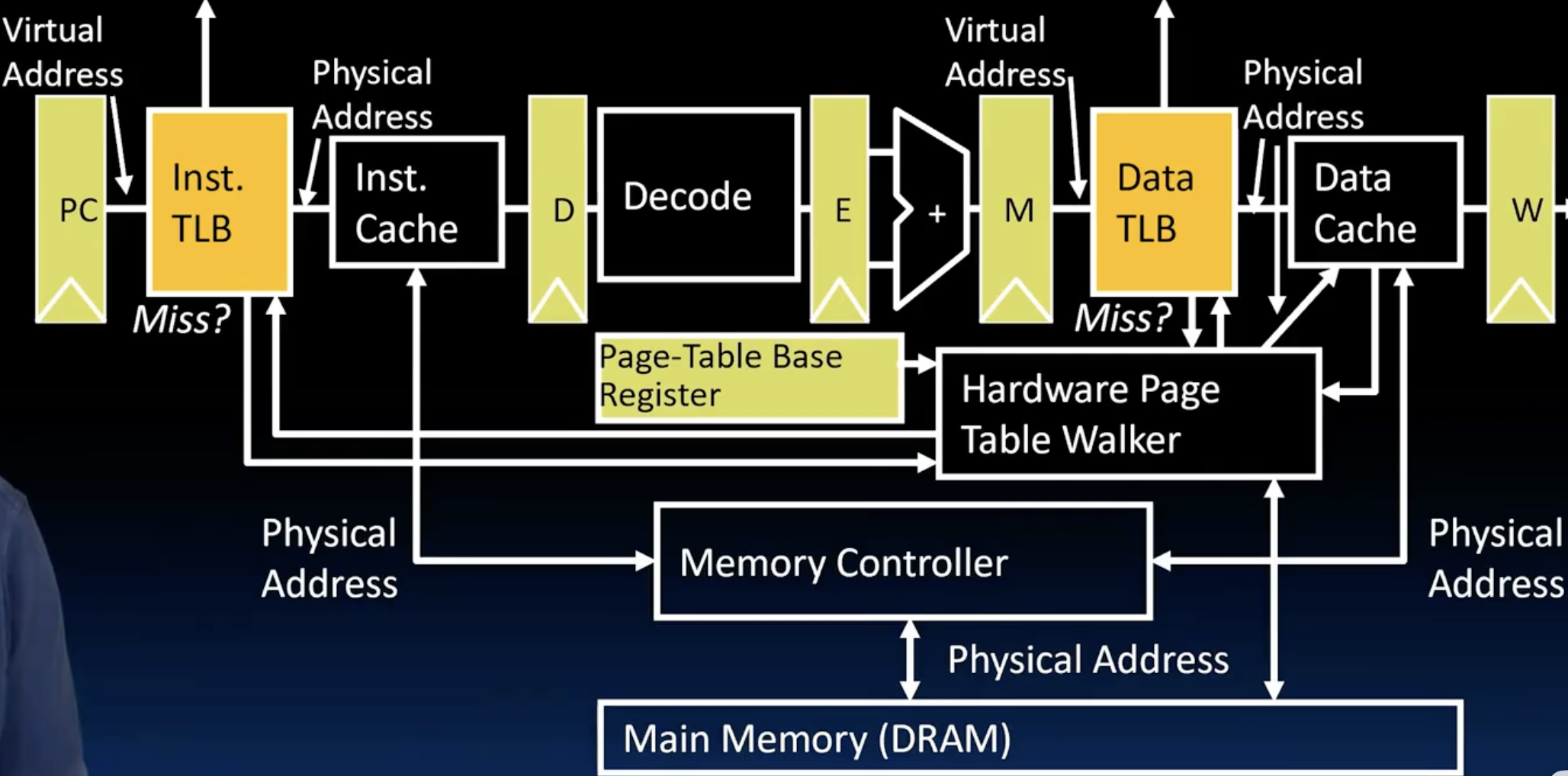
突然想到一个问题,如果某个进程的一个物理页被swap到磁盘上,那么需要修改它的page table entry中的DRAM/disk bit为0,如果这个PPN被TLB缓存了,那么我们需要将TLB中对应的entry的valid bit也修改为0,这样才能保证当这个进程再次访问这个虚拟地址时,能够出发page fault来将这个物理页从磁盘中移回内存并且update TLB,否则使用错误的PPN就炸了。
- 下图展示了Address Translation的各种分支:
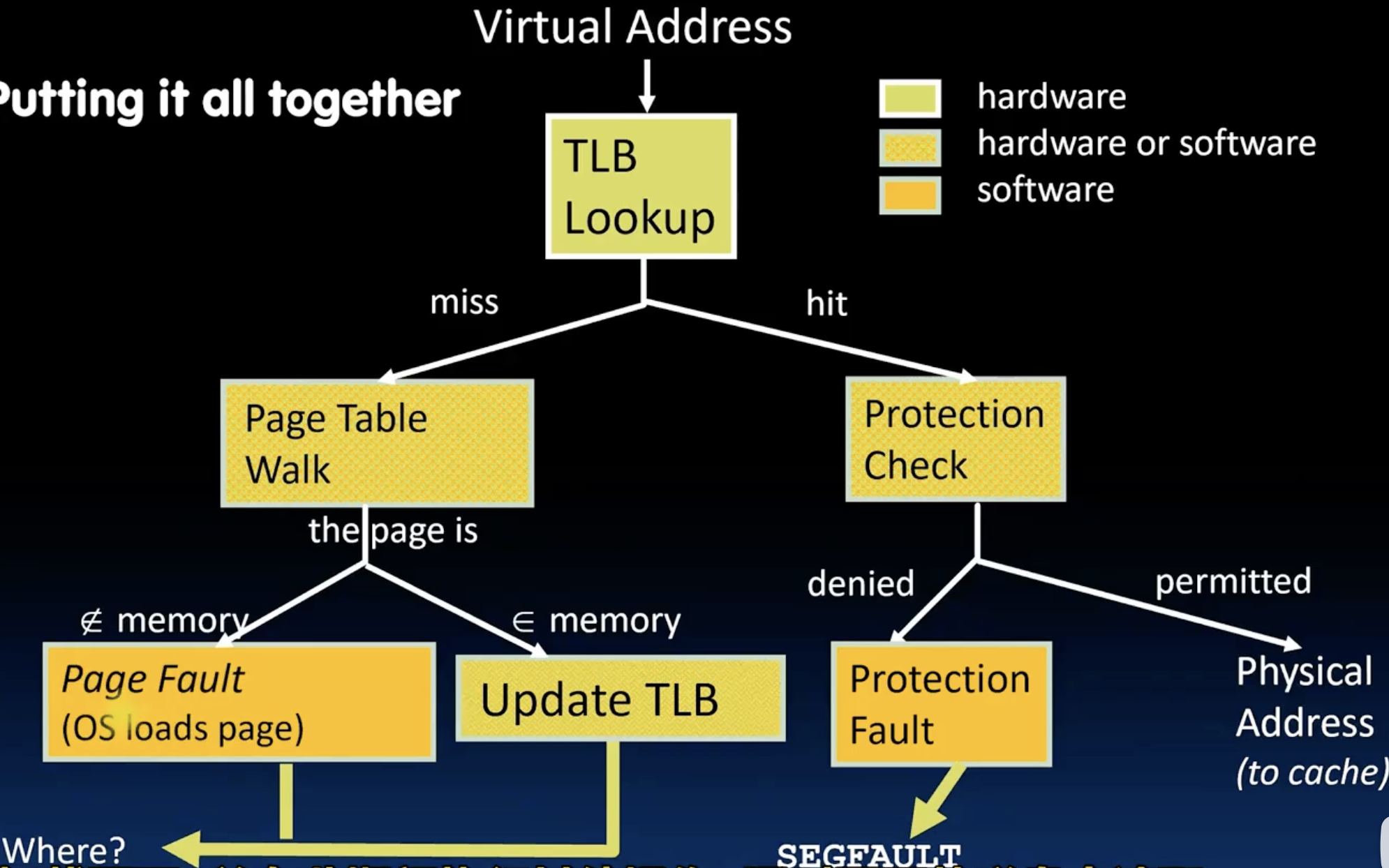
在这个图中,TLB的查找通过硬件实现,Page Table Walker和Protection Check可硬可软,现代基本都直接用硬件实现,更快速。对于Page Fault和Protection Fault的处理则需要OS的参与。我其实有一个疑问,就是对于上面提到过的一些被swap的页,它TLB的valid bit被设置为0,如果TLB查找到它了,为什么不直接触发page fault来处理呢?图中不是相当于多走了一个walker吗?算了,多一事不如少一事😭,valid=0就直接判断miss然后走Walker好了。
Modern Virtual Memory Systems
- Illusion of a large, private,uniform store🤣
- Protection & Privacy : several users/processes, each with their private address space.
- Demand Paging: Provides the ability to run programs larger than the primary memory. Hide differences in machine configurations.
- 好处这么多,代价就是从VA到PA转换的开销,TLB就是为了减少这个开销诞生的。Page Table的设计让VA到PA的转换得以实现,TLB的设计是为了加速这个转换的过程的,multi-level page table的设计则是为了节省空间。
- 对于context switch来说(通常由timer或者外部信号触发),我们需要保存当前进程的pc、registers、SPTBR等信息,然后加载新进程的pc、registers、SPTBR等信息,这样就完成了进程的切换了。对于TLB呢,直接把所有entry的valid bit都设置为0就好了,这样就保证了新进程访问任何虚拟地址都会触发TLB miss来重新加载对应的PPN了。
哎woc,这似乎回答了上面的疑问,即tag匹配但是valid bit是0的情况,还真不一定是swap导致的,也许阴差阳错就在context switch之后发生了,这个时候就得用新的SPTBR走一趟Walker了,因为此时真的有可能已经allocated了一个有效的物理页了(新进程的)!!!
VM Performance
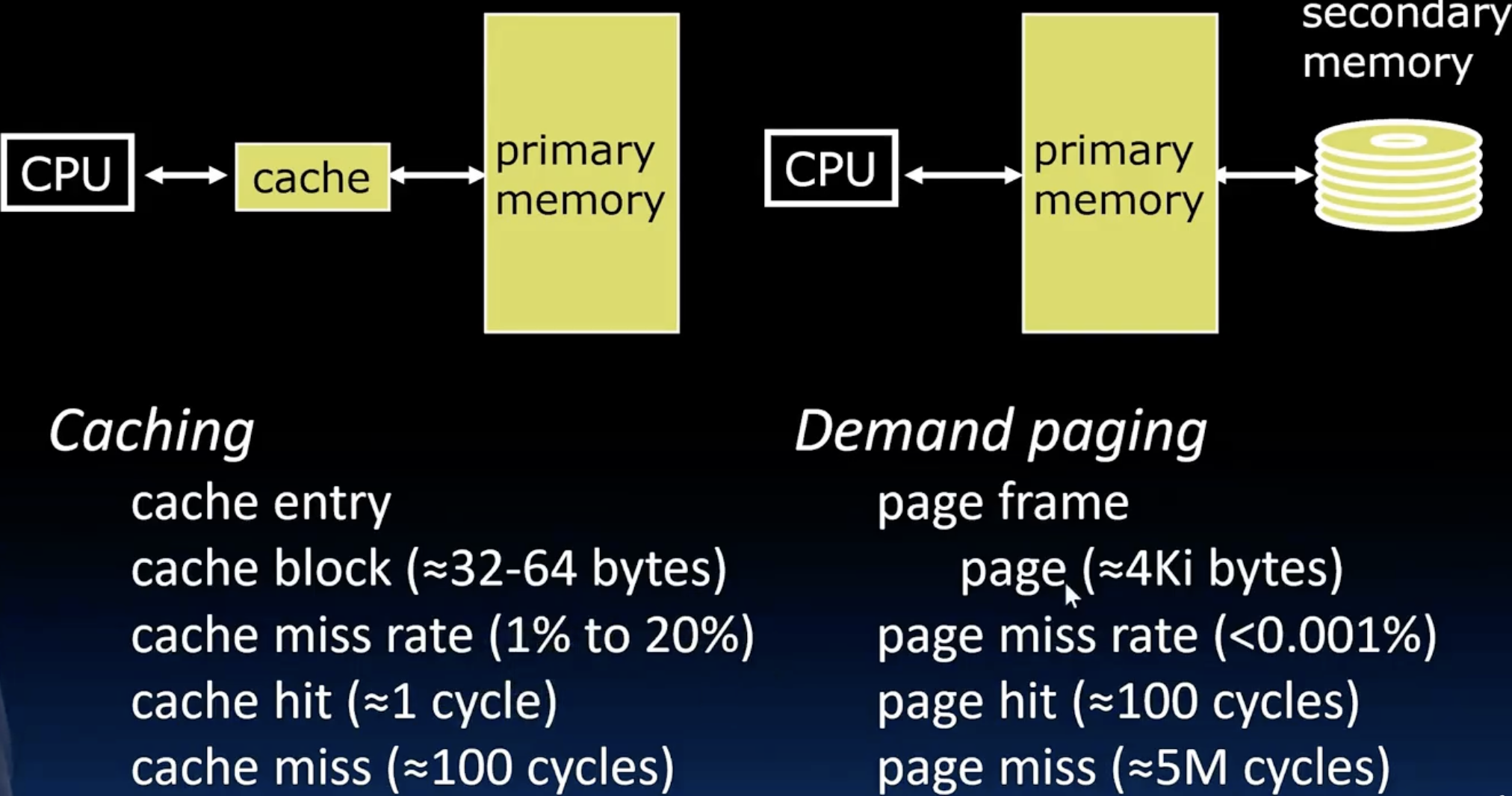
- 现在我们已经对VM有了充分了解,是时候衡量一个VM的性能了,如何衡量呢,可以发现VM和Cache十分相似,于是我们可以用同样的方法来衡量。
| |
- 在上一讲中我们列出了VM在memory hierarchy中的位置是DRAM和磁盘之间,因为VM可以通过page在DRAM和磁盘之间进行swap。于是如下图所示, 我们需要考虑page在内存中不存在的情况。
| |