引
- 在开启IO篇章前,我们回想一下在CS61c中我们已经干了什么,我们从最基础的C语言开始,并在project 1中实现了一个简单的"life game",然后我们学习了汇编语言,并在project 2中实现了一个简单的minist汇编识别网络,接着我们学习了ISA和CPU架构,在project 3中设计了一个简单的CPU,进一步学习了如何添加cache,如何添加虚拟内存。为了得到一个完整意义上的计算机,我们还缺少一个重要组成部分,即I/O设备。
- 只有加上I/O设备,我们才能让计算机连接键盘、鼠标,并且在显示器上显示结果,或者将其连接到网络,本文将介绍如何实现计算机和I/O设备的交互!
How to interact with Devices ?
- Assume a program running on a CPU, how can it interact with devices? For example, how can it read a character from the keyboard, or write something to the display?
- 为此,有人提出了I/O Interface的概念,I/O Interface是CPU和设备之间的一个抽象层,CPU通过I/O Interface来访问设备,而设备通过I/O Interface来与CPU通信。I/O Interface提供了一套统一的接口,让CPU可以通过读写特定的地址来访问设备,而不需要关心设备的具体实现细节。
Instruction Set Architecture for I/O
- What must processor do for I/O
- Input: Read a sequence of bytes
- Output: Write a sequence of bytes
- Interface options:
- 为每一个设备设计特殊的指令,但这是不现实的,因为设备经常更新换代,所以旧指令会过时,这与我们设计ISA的初衷是相悖的(我们希望一套ISA能用很久)。
- Memory mapped I/O: 将设备映射到内存地址空间中,CPU通过读写特定的内存地址来访问设备,这样就不需要为每个设备设计特殊的指令了。
Memory Mapped I/O
- Certain addresses are not ‘regular memory’
- Instead, they correspond to registers in I/O devices
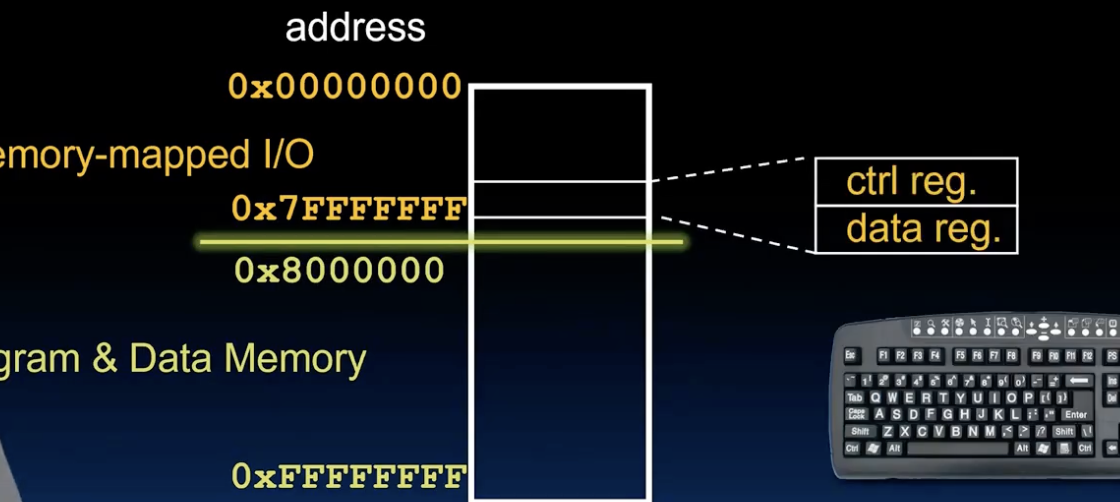
如图所示,通常来说主内存的较低地址区中有部分地址被保留给I/O设备使用,这些地址直接映射到每个I/O设备寄存器的物理接口上,读这些地址相当于直接读取寄存器的实时状态. 换句话说,之前每个设备有自己特殊指令来访问,现在是通过不同设备有不同地址来访问,CPU通过读写这些特定的地址来与设备通信。
Processor-I/O Speed Mismatch
- 假设我们有一个 1 GHz microprocessor I/O throughput, 如果读写可以在一个时钟时间完成,那么它的数据吞吐量就是 4 GiB/s (lw/sw)
- 然而一些典型的 I/O data rates:
- 10 B/s (keyboard)
- 3 MiB/s (Bluetooth 3.0)
- 0.06-1.25 GiB/s (USB 2/3.1)
- 7-250 MiB/s (Wifi, depends on standard)
- 125 MiB/s (G-bit Ethernet)
- 480 MiB/s (SATA3 HDD)
- 560 MiB/s (cutting edge SSD)
- 5 GiB/s (Thunderbolt 3)
- 32 GiB/s (High-end DDR4 DRAM)
- 64 GiB/s (HBM2 DRAM)
对于一个多核系统,可能存在多个核心同时需要往内存中读写数据,所以对内存的数据吞吐速率要求更高,为此诞生了HBM2 DRAM等高端内存技术。
由上述数据可知,大多数I/O设备的数据传输速率远远低于处理器的速度, 那么处理器如何判断设备是否准备好了呢?I/O Polling !
I/O Polling
Device registers generally serve two functions:
- Control Register, says it’s ok to read/write (I/O ready)
- Data Register, contains data.
Processor reads from Control Register in loop.
- Waiting for device to set Ready bit in control reg (0->1)
- Indicates “data available” or “ready to accept data”
Processor then loads from (input) or writes to (output) data register. Then Control register resets Ready bit to 0.
一个Polling loop的示例代码如下:
| |
- 以上的流程就是I/O Polling,处理器不断地轮询设备的控制寄存器,直到设备准备好为止,这种方式虽然简单,但效率很低.
比如,一个鼠标检测器需要每秒钟检测30次鼠标的状态,如果一次检测需要400cycles,那么每秒钟就是12k cycles,在处理器频率为1GHz的情况下,这个检测会占用0.0012%的处理器时间,可以接受。
再比如,一个磁盘每秒钟可以产生16MB的数据,如果每次polling处理16B的数据,那么每秒钟需要1M次polling,假设每次poll需要400个cycles,那么就是400M cycles/s, 占用处理器40%的时间,这就不可接受了。当然,问题一方面是polling这种原始方式很低效,另一方面是每次只处理16B数据太少了,导致polling次数过多。 由这个例子可以知道,只要是大数据流遇上了小data register,就会导致处理器必须进行高频率的polling,这时就需要引入更高效的I/O机制了。
I/O Interrupts
- 打个简单的比方:Polling就像是我们在家里开了一个派对,你每过几分钟就到门口看一下是否有客人来了,而人们很早之前就发明了门铃,门铃就是一个Interrupt,当有客人按门铃时,门铃会发出一个信号,告诉你有客人来了,这样你就不需要一直去门口看了。
- I/O Interrupts相比Polling的优势在于它让处理器不需要在设备准备好之前一直查询,只有当设备准备好时发出一个信号,处理器才会去处理这个事件,这样就大大提高了效率。
- 对于Low data rate, 比如键盘和鼠标,使用Interrupts是合适的。但是对于high data rate, 比如disk和network,由于Interrupts会导致进程切换的巨大开销,所以通常是start with interrupts, but switch to DMA(directly memory access) once data starts coming.
Programmed I/O (PIO)
- 定义:Programmed I/O 是指数据传输由 CPU 亲自执行指令来完成的方式。
- 工作方式:在 PIO 模式下,CPU 通过
lw/sw(或in/out)指令,亲手把数据从设备的数据寄存器搬到内存,或者从内存搬到设备。 - PIO 与 Polling 的关系:PIO 回答的是“谁搬数据”,Polling 回答的是“怎么知道该搬了”。它们经常一起出现——CPU 先通过 Polling 等待设备就绪,然后用 PIO 的方式亲手搬数据。
- PIO 与 Interrupts 的搭配:设备也可以通过中断通知 CPU 数据就绪,然后 CPU 仍然用 PIO 方式亲手搬数据。只是当数据量大时,这种组合效率太低。
- 解决办法:DMA(直接内存访问):DMA 让专用硬件控制器来搬数据,CPU 只负责发命令和收通知,从而从繁重的数据搬运中解放出来。
DMA
- 定义:DMA(Direct Memory Access)是一种让专用硬件控制器直接在设备和内存之间搬数据的技术,CPU 只负责发命令和收通知。
- New hardware: The DMA Engine, 它包含了一些由CPU写入的寄存器:
- Memory Address to place data.
- the number of bytes to transfer.
- I/O device to transfer from/to.
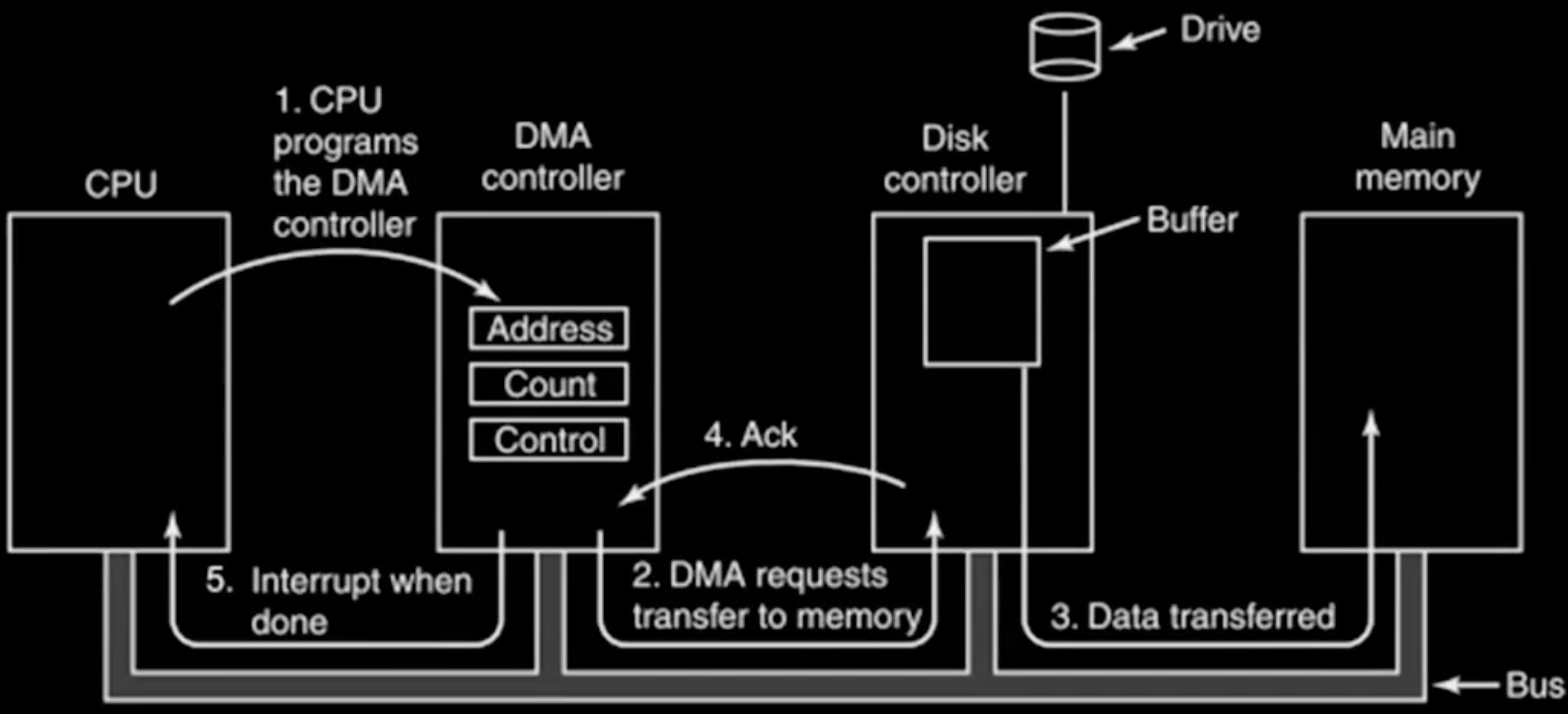
如图所示是DMA的工作流程,
- 对于Ingoing data, CPU 收到一个interrupt,告诉它设备有数据了,然后CPU把DMA Engine的寄存器写好,告诉它数据要放到内存的哪个位置,要传入多少字节,以及数据来自哪个设备,然后CPU回去执行其他任务,DMA独立地把数据从设备搬到内存,搬完之后再发一个interrupt告诉CPU数据已经搬好了。
- 对于Outgoing data, (通常是软件主动发起)CPU决定发送数据,先确认device准备就绪,然后写好DMA Engine的寄存器,告诉它数据要从内存的哪个位置搬到设备,要搬多少字节,以及数据要传到哪个设备,然后CPU回去执行其他任务,DMA独立地把数据从内存搬到设备,搬完之后再发一个interrupt告诉CPU数据已经搬好了。
Where in the memory hierarchy do we plug in the DMA engine?
- 直接连到L1上,好处是读写都是最新的数据,坏处是占用L1本就精贵的空间,CPU不活啦。
- 直接连到内存上,好处是不会占用CPU的cache空间,也就不会污染cache,坏处是读写不能及时更新,比如L1中有最新CPU写入的数据,但DMA在内存中读取的是旧数据;DMA在内存中写入了新数据,但CPU在L1中读取的还是旧数据。所以需要手动管理DMA和CPU之间数据一致性问题。
以上是两种极端情况,实际中我们偏向后者,因为DMA通常是大块数据传输,直接连到内存上更合适,虽然需要手动管理数据一致性,但这是可以接受的。
Networking
- ~~~, 这部分我就偷个懒了🥵
Lab08
- 基于Camera.jar和VMSIM两个模拟器的lab,只要能理解VA到PA的过程就能完成,Camera.jar我已经放到了仓库的lab08下,在README中也有提到关于用java8运行VMSIM的一个坑。