引
- 从本篇开始,我们将进入一个新的板块——parallelism (并行计算)。学完之前的课程,我们可以说已经完全理解一台计算机了,现在我们要让这台计算机更加强大。
- parallel有很多类型,比如一个cpu核,可以进行多线程并行;对于一个流水线,我们可以多指令并行。然而,随着流水线的不断加深,cpu的功耗也会增加,已经达到了不可接受的程度,所以人们开始思考是否可以并行计算多个数据来提高性能。比如两个向量相加,我们可以并行执行所有元素的加法,从而提高效率。
Application: Machine Learning
- 在机器学习或者更具体的深度学习中,我们通常需要进行大量矩阵运算,比如矩阵乘法、卷积等,这些操作都可以通过并行计算来加速。
- 比如矩阵乘法,作为一种在image filter,machien learning中很常见的操作,早在C语言尚没有流行时(当时流行一种叫FORTRAN的语言),就有了专门的dgemm指令(double-precision floating-point matrix multiplication), 足以显示该操作的重要性。
Matrices
- 对于两个矩阵A和B(均为NxN)的乘法,假设结果是C矩阵,那么C矩阵中的每个元素C[i][j]都是A矩阵的第i行和B矩阵的第j列的点积,这里进行的N个乘法显然是可以同时计算的,同理,C中的每一个元素的计算也是可以同时进行的,因此矩阵乘法是一个非常适合并行计算的操作。理想情况下(无穷加法乘法器和缓存),矩阵乘法的时间复杂度可以从$O(N^3)$降到$O(\log N)$ ?! 原因是即便有足够的处理器核心来并行计算所有东西,最后的加法还是有下界的,当形成一个树形加法结构时,时间复杂度是$O(\log N)$的。
Parallelism
Matrix Multiplication
- 对于正常的矩阵乘法:
| |
| |
- 我们可以设定timer,统计两个程序的运行时间t,然后$2\cdot N^3 / t$就是FLOPS(floating-point operations per second),从而反应两个程序的效率。结果如下表所示,C语言版本竟然比Python版本快了大约240倍!
| N | C[GLOPS] | Python[GLOPS] |
|---|---|---|
| 32 | 1.30 | 0.0054 |
| 160 | 1.30 | 0.0055 |
| 480 | 1.32 | 0.0054 |
| 960 | 0.91 | 0.0053 |
- C比python快了244倍可以理解,但是这两列数据看起来怪怪的?
对C来说,当N较小时,效率就是CPU的最大频率,所以不变;当N很大时,由于缓存放不下所有的数据,所以有一个延迟,效率就会下降。对Python来说,当N不是特别大时,时间成本主要是解释器开销,时间和N^3成正比,所以效率不变?
Flynn’s Taxonomy
- Choice of hardware and software parallelism are independent
- Concurrent software can also run on serial hardware
- Sequential software can also run on parallel hardware
- Flynn’s taxonomy 根据指令流和数据流的不同,将计算机系统分为4类:

SIMD: specialized function units (hardware), for handling lock-step calculatiions involving arrays. 常用于Scientific computing, machine learning, signal processing …
- 下图展示了4种类型的工作方式:
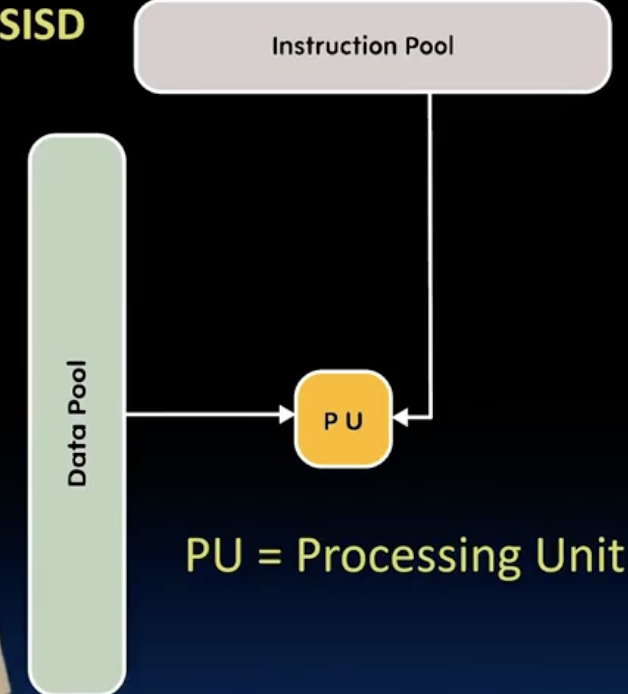
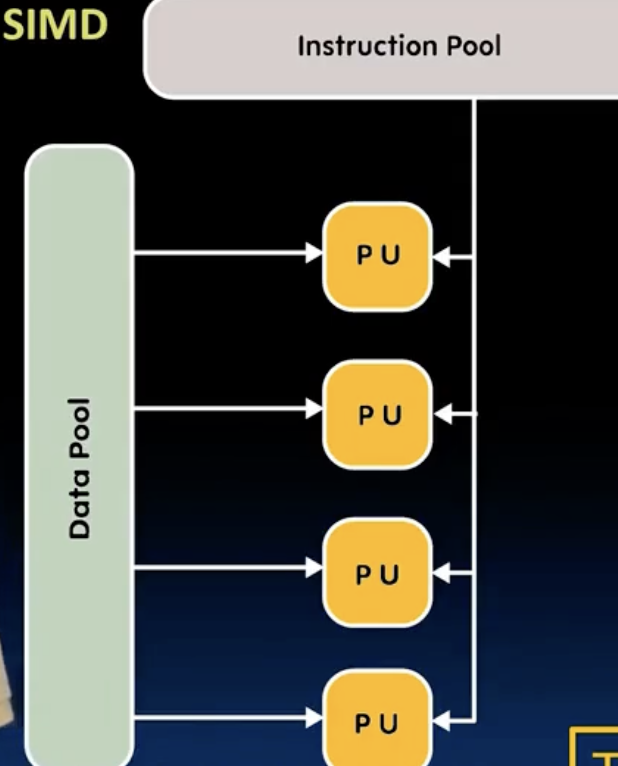
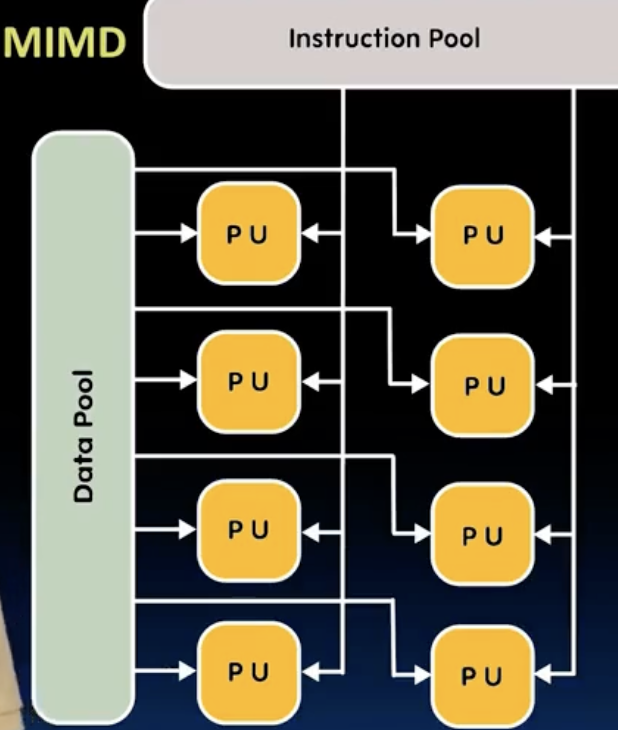
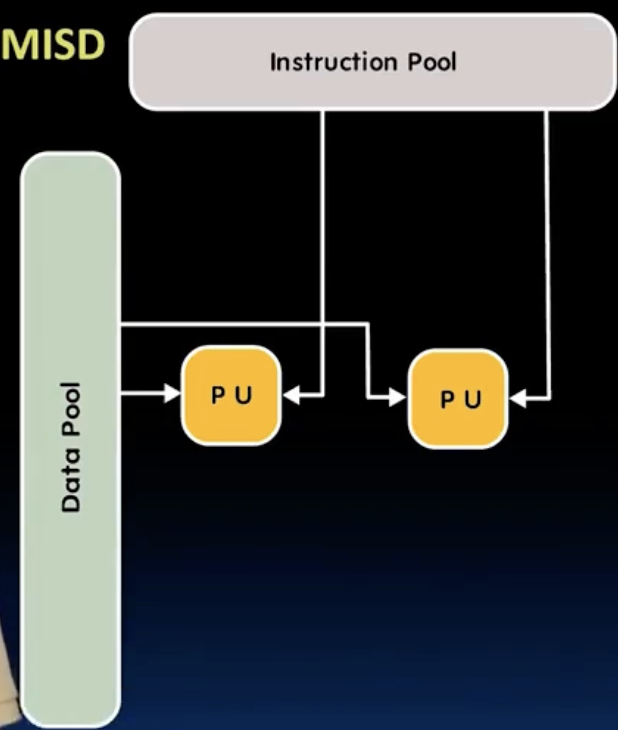
其中,SIMD通过集成多个硬件单元来实现数据并行,MIMD则通过多个处理器核心来实现指令并行,可以看成是多个SIMD的组合。MISD比较少见,mainly of historical interest only.
SIMD Architectures
- 下图展示了Inter SIMD架构的进化史:
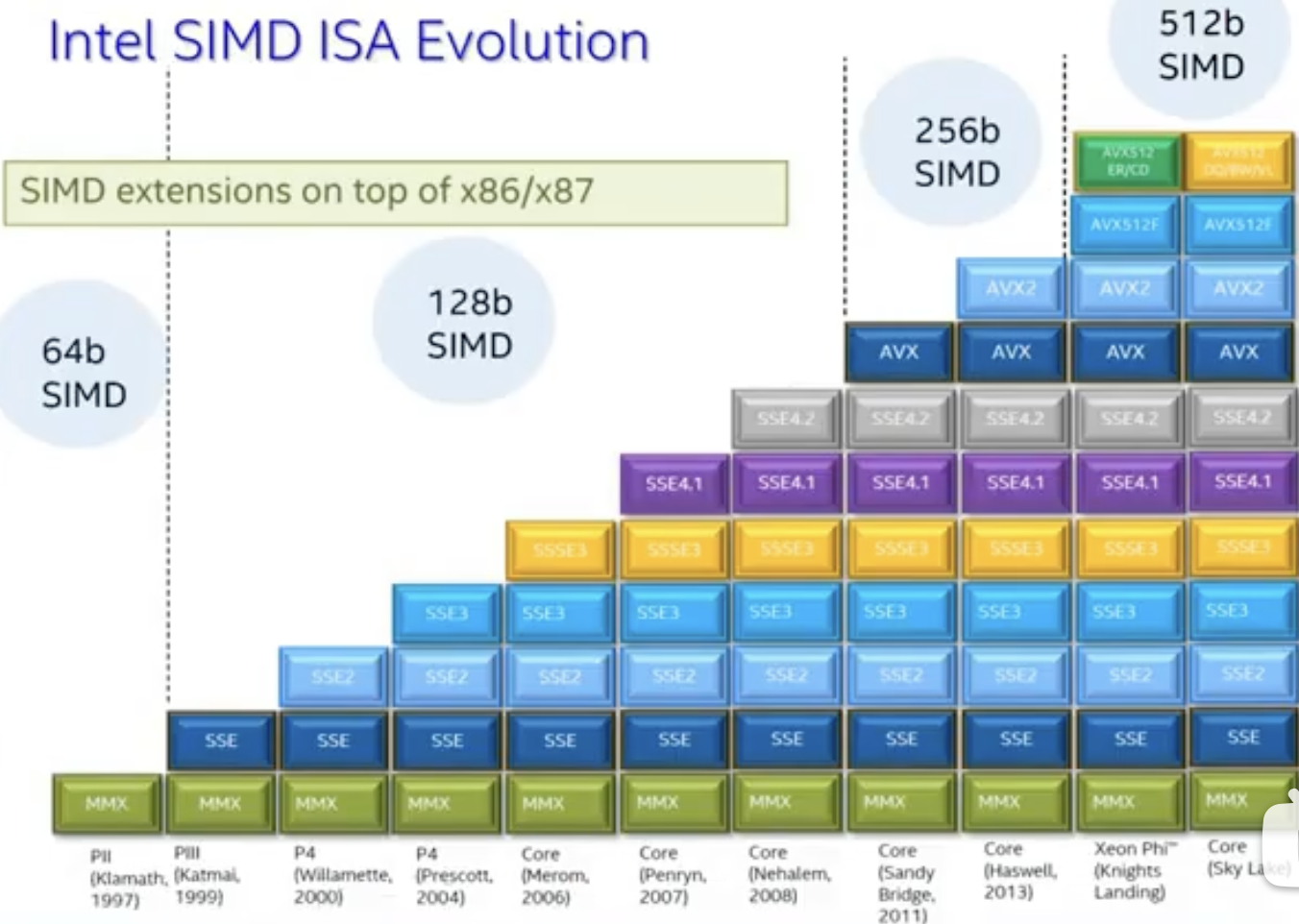
SIMD本质上是将多个数据同时加载到寄存器中,然后并行计算。
由于Inter坚持向后兼容,所以你会发现每一代新SIMD指令集都包含了之前的指令集,这样就保证了旧软件可以在新硬件上运行(即在本就很复杂的指令集上增加新指令集)。同时,随着SIMD指令集的不断发展,所需要的寄存器也不断增加和扩展。
- 对于之前矩阵乘法例子,我们使用AVX指令集来加速:
| N | AVX[GLOPS] | C[GLOPS] | Python[GLOPS] |
|---|---|---|---|
| 32 | 4.56 | 1.30 | 0.0054 |
| 160 | 5.47 | 1.30 | 0.0055 |
| 480 | 5.27 | 1.32 | 0.0054 |
| 960 | 3.64 | 0.91 | 0.0053 |
可以发现 AVX 版本的效率比普通 C 代码高了大约 4 倍,在 N 较大时同样受到缓存限制,性能下降。理论上,这颗 Intel i7-5557U 的单核浮点峰值约为 25 GFLOPS:3.1 GHz × 2 instructions/cycle × 4 mults/inst = 24.8 GFLOPS。其中 3.1 GHz 是最大睿频频率,2 instructions/cycle 是超标量发射数(这里特指两个 AVX 向量执行单元),4 mults/inst 是指一条 AVX 指令可以同时做 4 个双精度乘法。实际测得的性能(3.6–5.5 GFLOPS)远低于理论峰值,可能的原因包括:CPU 没有跑满最高频率、没有同时利用两个 AVX 单元、内存带宽受限,或者编译器生成的指令流没有完美填满流水线。但无论如何,AVX 相比普通标量 C 代码确实带来了接近 4 倍的加速,SIMD 的优势是明确的。
- 在SEE中,有专门的向量寄存器xmm0-xmm7,每一个都是128位,可以同时存储4个32位的单精度浮点数或者2个64位的双精度浮点数。在AVX中,有ymm0-ymm15,每一个都是256位。在AVX512中,有zmm0-zmm31,每一个是512位!如果你拥有一台linux电脑/服务器,或者是虚拟机,你可以使用lscpu命令在flags中查看是否支持avx512.
SIMD Array Processing
- 下面,让我们看看SIMD具体如何加速Array处理的吧!
| |
- 再举一个SIMD的汇编例子:
| |
- 通常来说,编译器会自动将一些简单的循环自动向量化(auto-vectorization),也就是自动将标量代码转换为SIMD代码,但对于更复杂的代码,编译器可能无法正确识别并行机会,这时我们就可以使用intrinsics或者直接手写汇编来利用SIMD指令。
| |
Matrix Multiply Example
至此,我们知道了SIMD扩展是如何工作的了,它们是如何被指令集架构支持的,如何在硬件中实现,以及如何在汇编中使用这些指令,或者在C代码中使用内联函数。所以,让我们看一个例子,将所有东西融合,用SIMD实现一个Matrix Multiply吧!
如图, 假设内存是列优先,我们首先计算黄框部分。

| |
这里提一嘴RISC-V,课程视频中(2020年)它的SIMD指令集处于草案阶段,但是由于还没有实际硬件支持,所以没有机会做RISC-V的SIMD编程😭
现在(2026),RISC-V的V系列向量指令集已经正式发布,并且有一些商用处理器已经支持!
Lab09
在lab09中,我们将学习如何在实际c代码中运用SIMD指令来加速,在exercise 1中,我们需要到inter官方文档中找到要求的intrinsics,熟悉它们的用法。在exercise 2中,我们将利用这些intrinsics来加速一个数组的求和,即每次都使用一个SIMD指令来同时处理4个元素,从而提高效率。在exercise 3中,我们将运用Loop Unrolling技巧一次循环做多个SIMD指令,处理更多元素,减少循环开销,进一步提升效率。
以下内容纯个人分析,未经验证,仅供参考🥵:
你也许会觉得exercise 2中的SIMD版本和普通版本Loop Unrolling是一个道理,即每次循环都是处理了4个元素,然而并非,SIMD版本下我们可以每次独立对4个元素进行加法,但是普通Loop Unrolling中我们每次获取4个元素后必须将它们加到一起,有一个依赖关系,所以仍是长路径。
试想在sum_unrolled函数中,初始化4个变量,sum1,sum2,sum3,sum4, 每次循环分别将4个元素加到这4个变量中,最后再将这4个变量加在一起,这样就完全消除了依赖关系,此时的sum_unrolled_optimal确实和SIMD没有逻辑上的区别。然而,这只是理论上没有区别,实际上由于硬件执行层面是一条一条指令发射的,所以4个加法仍然有先后顺序,无法完全并行执行,所以性能上不会有很大提升(有可能是add比较快,依赖延迟小)。
而SIMD真正做到了发射一条指令,同时加载4个元素,同时做4个加法,真正实现了并行计算,所以性能提升是非常显著的。如果再用上Loop Unrolling的话,一次循环发射多条SIMD指令,性能就更好了。此时,再初始化4个128位的寄存器,分为temp1,temp2,temp3,temp4,消除依赖关系,竟然有0.2s的提升!可能是128位SIMD加法的延迟大于普通加法?所以在向量加法器充足情况下,消除依赖关系的效果就更明显了。
其实这个就是data hazards, 只不过普通add延迟小,所以无法提现消除data hazards的效果,而SIMD加法延迟大,所以消除data hazards的效果就很明显了。