引
- 跳出编程方法,如何加快程序运行呢?首先,可以尝试提高时钟频率。然而,受限于功耗与散热瓶颈,单纯依靠提升频率的道路已越走越窄,主流处理器的全核满载频率大多仍徘徊在5GHz以下。其次,是挖掘指令级并行(ILP),例如采用SIMD指令集和超标量发射技术。最后,是提升线程级并行(TLP),这主要通过增加物理核心数量或采用同时多线程(如超线程技术)来实现。上一篇我们已学习了指令级并行,现在将进入线程级并行的世界。
Multicore CPU
- 下图展示了一个具有两个核心的CPU架构。每个核心都配备了自己的流水线和寄存器文件,能够独立执行指令流。这样的设计允许我们同时运行多个线程,从而提高整体系统的吞吐量和响应能力。
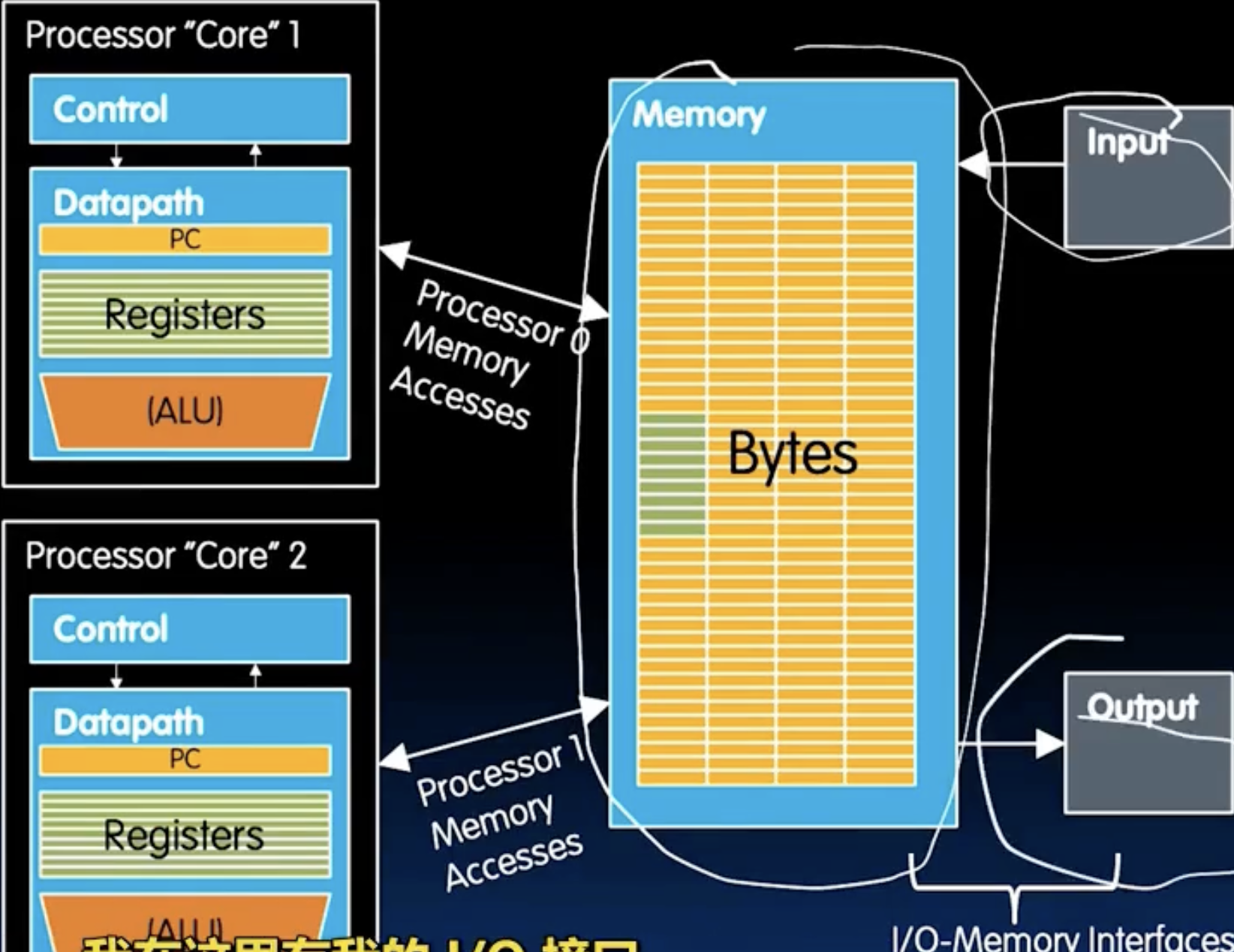
Multiprocessor Execution Model
Each core executes its own instructions.
Separate resources (not shared):
- Datapath (pc, registers, AlU)
- Highest level cache (L1 and L2)
Shared resources:
- Main memory (DRAM)
- L3 cache (often on same silicon chip)
Shared memory
- Each “core” has access to the entire memory in the processor
- Specia hardware keeps caches consistent !!!
- 各个core可以很容易的通过共享内存进行通信,甚至可以通过共享内存来实现负载均衡(load balancing),比如一个core忙于计算,另一个core空闲,那么可以将一些任务从忙的core迁移到空闲的core上来执行,从而提高整体性能。然而,由于内存访问的延迟较高,频繁的内存访问可能会成为性能瓶颈。
Two ways to use a multiprocessor:
- Job-level parallelism: 各个core执行不同的程序,互不干扰。
- Partition work of single task between several cores: 例如一个巨大的矩阵乘法任务,可以将矩阵划分成多个子块,每个core负责计算其中一个子块,从而加快计算速度。
Transition to Multicore
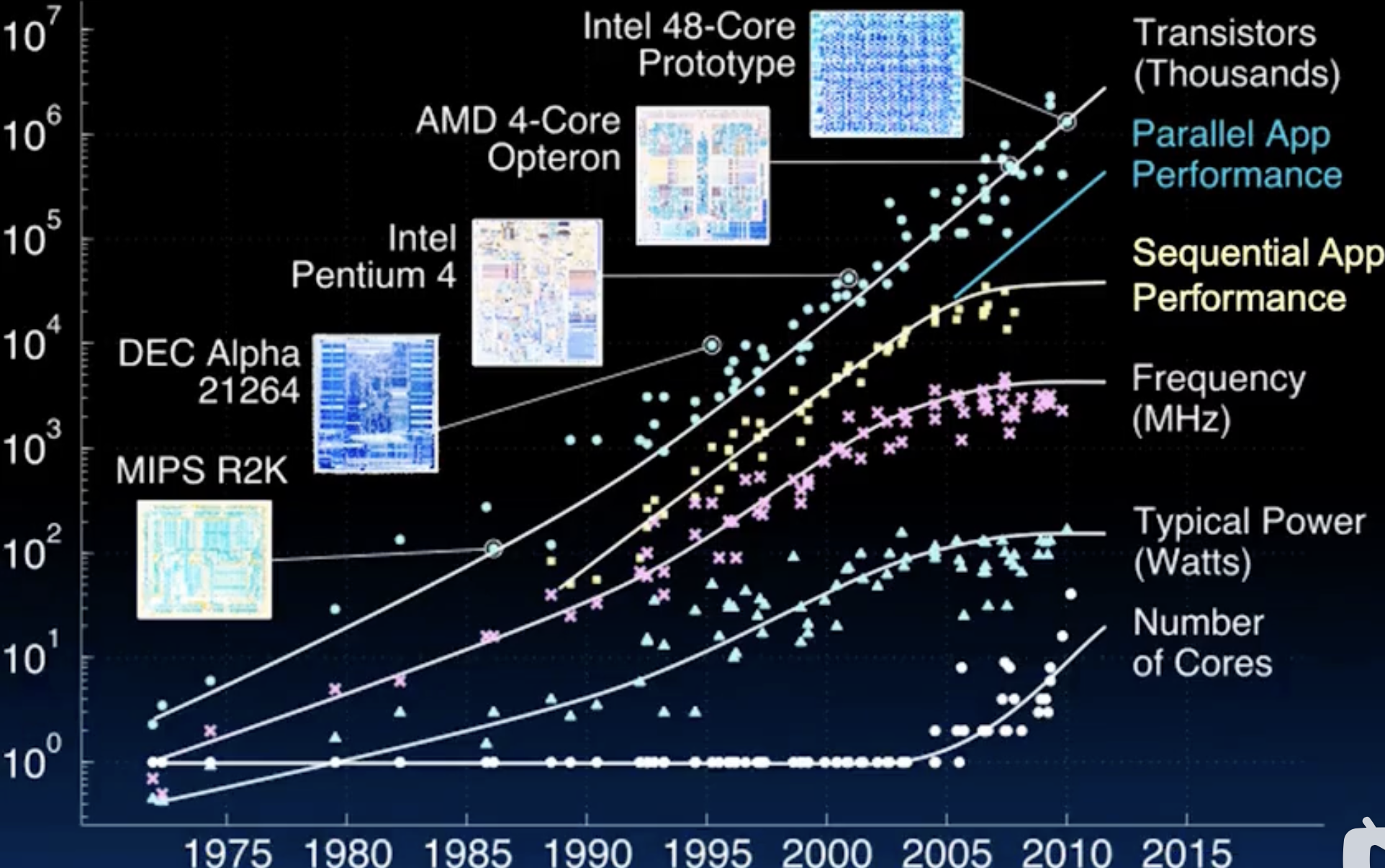
如图所示,从上世纪70年代开始直到现在,摩尔定律依旧坚挺,晶体管越做越小。然而,Dennard Scaling在2005年左右就已经失效了(由于一些物理原因),导致CPU频率无法进一步提升,如果强制提升频率会导致功耗爆炸。所以图中的Frequency和Typical Power在2005年左右开始趋于平稳。
Sequential APP Performance指的是顺序执行(单线程)应用程序的性能,即程序只在一个CPU核心上依次执行指令时的运行速度。由于2005前后CPU频率停滞不前,单线程性能提升也变得非常有限。以前,lazy的程序员在写完代码后,啥也不用干,过几年就能享受性能提升,但现在不行了。
于是,CPU厂商开始增加核心数量来提升性能,Number of Cores开始指数级上升,于是Parallel APP Performance能够继续提升,所以,如果你想在这个时代当一个lazy的程序员,想要享受免费的性能提升,那么请掌握并行编程吧!
Promising Multicore Performance
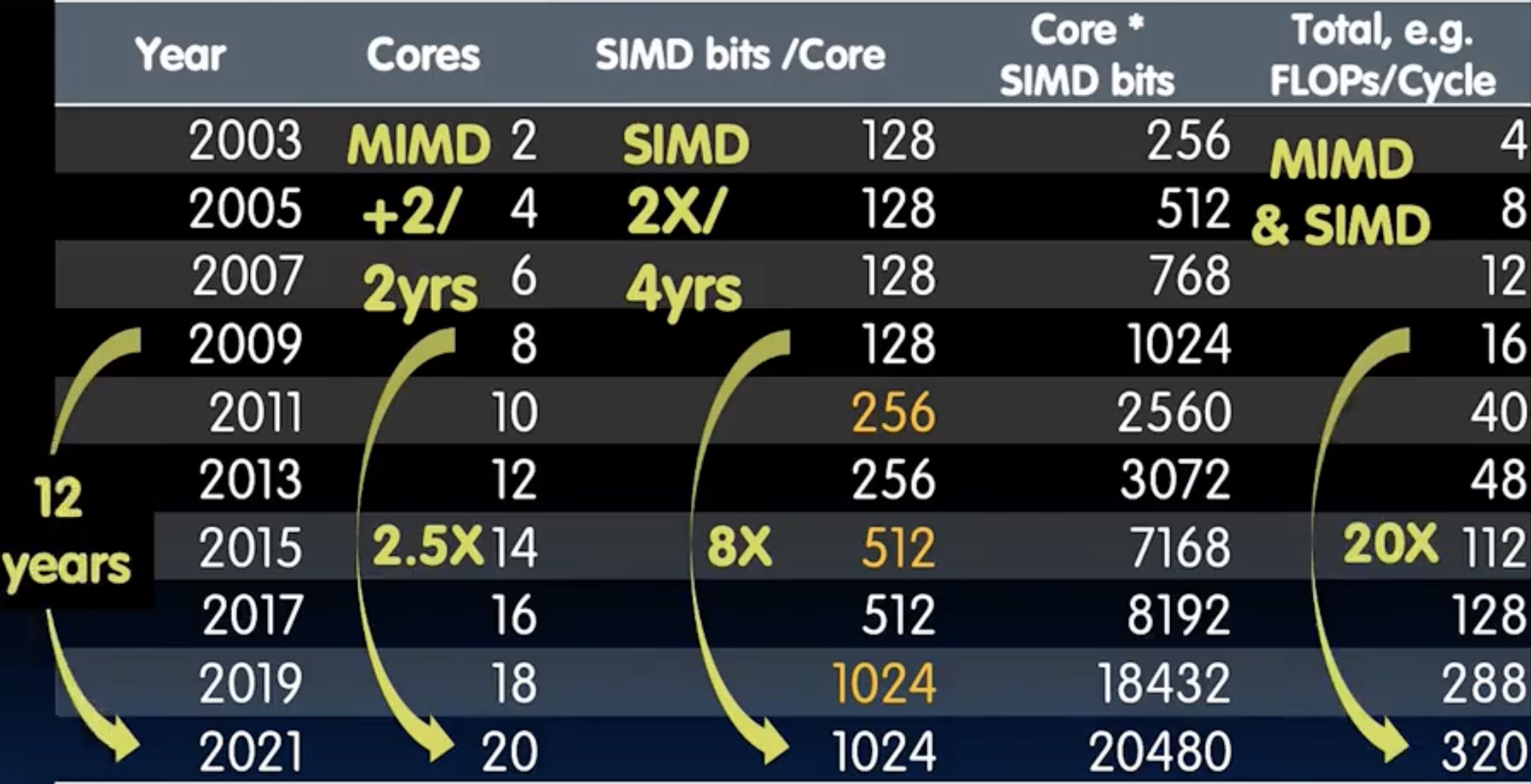
从2009到2021年,Cores核心数量从8涨到20个(2.5x),SIMD bits从128涨到1024(8x),也就是说每周期能进行的浮点运算次数涨了20倍!hhh,请掌握并行编程吧。
Threads
- A thread stands for “thread of execution”, is a single stream of instructions. A program/process can split, or fork itself into separate threads, which can (in theory) excecute simultaneously.
- 问题来了,如果只有一个CPU核心,那么这些线程只能轮流执行,无法真正并行,这就是所谓的Time Sharing. 此时,操作系统会通过时间片轮转的方式来切换线程的执行,让每个线程都能得到一定的CPU时间,从而实现多任务处理的效果。
注意OS也是一个程序,但不是时时刻刻都在运行,当计时器或者其他信号触发时,OS被唤醒来调度线程,OS会保存当前线程的状态(寄存器、程序计数器等),然后切换到另一个线程继续执行,这样就实现了多线程的并发执行。
其他信号比如cache miss, user input, network access,这些情况下为了不让CPU核心空闲,OS会切换到其他线程来执行,等到之前的线程准备好继续执行时再切回来。另一种计时,比如1ms切换一次,是为了让每个程序都能公平使用CPU,让人眼觉得所有程序都在同时运行。
如果线程太多,导致某个程序等待时间过长,用户就会感觉“卡顿”。
通常,一个线程有自己独立的寄存器、PC、并且能访问内存。我们称core上正在执行的线程为"hardware thread", 而其他等待中的线程为"software thread".
Multithreading
- background:上文提到,当一个线程blocked时,os会进行context switch来切换到另一个线程继续执行,但是这个过程需要保存和恢复寄存器状态,需要访存!!!Time Consuming!!! 为了节省这个访存时间,直接搬一套寄存器到CPU核心上,不就行了?于是就有了Multithreading的概念。
- Multithreading is a technique that allows multiple threads to run concurrently on a single CPU core,即 Hyper-threading —— 超线程。
- 一个核心每一刻都运行多个线程,每个线程都有自己的寄存器和PC,但execution unit, cache等资源是共享的。所以,我们可以认为一个核心上有多个hardware thread, 即有多个logical core. 当然,多个线程共享execution unit和cache等资源(比如A用ALU,B用FPU或是A在访存,B随意用),所以性能提升不是线性的(存在硬件竞争),通常在10%~30%左右。
- 运行
sysctl hw | grep cpu可以查看你电脑(macos)的hw.physicalcpu和hw.logicalcpu(如果是linux,请用lscpu). 如果logical core数量是physical core数量的两倍,那么说明你的CPU支持超线程(2x)技术。
超线程技术只需要增加几个寄存器,1% more hareware, but 10% better performance. Multicore技术需要增加更多的核心,50% more hardware, but 2x better performance. 在现代英特尔架构中,两种技术通常是结合使用的,既有多个物理核心,每个核心又支持超线程,从而进一步提升性能。