Hardware Synchronization
Solution:
- Atomic read/write
- 即 Read & write in single instruction. No other access permitted between read and write.一般都涉及到共享内存。
Common implementation:
- Atomic swap of register <-> memory
- Pair of instructions for “linked” read and write, write fails if memory location has been “tampered” with after linked read.
下面以 RISC-V 的AMO(Atomic Memory Operations)为例,介绍一下第一种实现方法。AMOs atomically perform an operation on an operand in memory and set the destination register to the original memory value.
| |
上面的代码实现了一个简单的自旋锁,当一个线程想要进入临界区时,它会尝试获取锁值,如果是0,说明锁是空闲的,它就会将锁值设置为1并进入临界区;如果锁值已经是1,就会反复尝试获取锁。这和上一篇提到用while(lock != 0 )的C语言实现最大的区别就是,这里我们使用了AMO指令来保证原子性,而不是简单的读写操作。AMO通常会在执行指令时锁住对应的内存地址,确保在指令执行期间其他线程无法访问这个地址,从而实现了原子性。
OpenMP Locks
- 有人也许会问,啊,难道我们一定要用RISC-V晦涩的AMO指令来实现吗,有没有简单点的办法呢?当然有!比如OpenMP就提供了专门的锁机制,叫做omp_lock_t, 示例如下:
| |
上面代码中展示了如何在OpenMP中使用锁来保护临界区,十分方便。OpenMP甚至提供了critical指令来进一步简化锁的使用,示例如下:
| |
Deadlock
- 可能会发生死锁的情况:当一个线程持有锁A并等待锁B,而另一个线程持有锁B并等待锁A时,就会发生死锁。
- 比如著名的 Dining Philosopher’s Problem:
- Think until the left fork is available; when it is, pick it up
- Think until the right fork is available; when it is, pick it up
- When both forks are held, eat for a fixed amount of time
- Then, put the right fork down
- Then, put the left fork down
- Repeat from the beginning
- 可能发生的情况:每个人都拿起了左边的叉子,此时每个人都在等待右边的叉子,但是右边的叉子被别人拿着了,因此所有人都在等待,无法继续执行下去🤣
OpenMP Timing
- OpenMP提供了
double omp_get_wtime(void)来获取当前wall clock time,单位为s。 - Time is measured per thread ! Two distinct threads may return different values for the same call to omp_get_wtime().
- 这个函数返回的是一个相对时间,至于起点是哪天,谁也不知道,我们也不管它,反正调用两次求时间差即可。
Shared Memory and Caches
- SMP: (Shared Memory) Symmetric Multiprocessor
- Two or more identical CPUs/Cores
- Single shared coherent memory
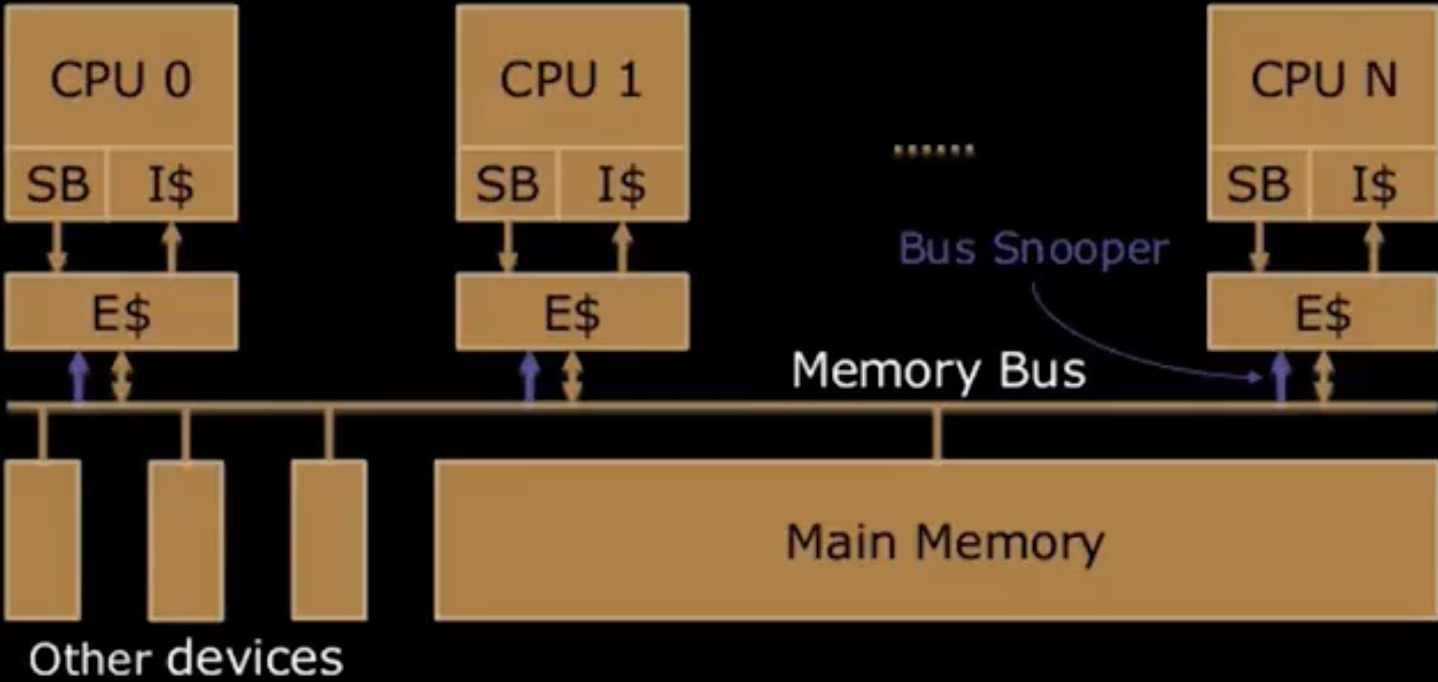
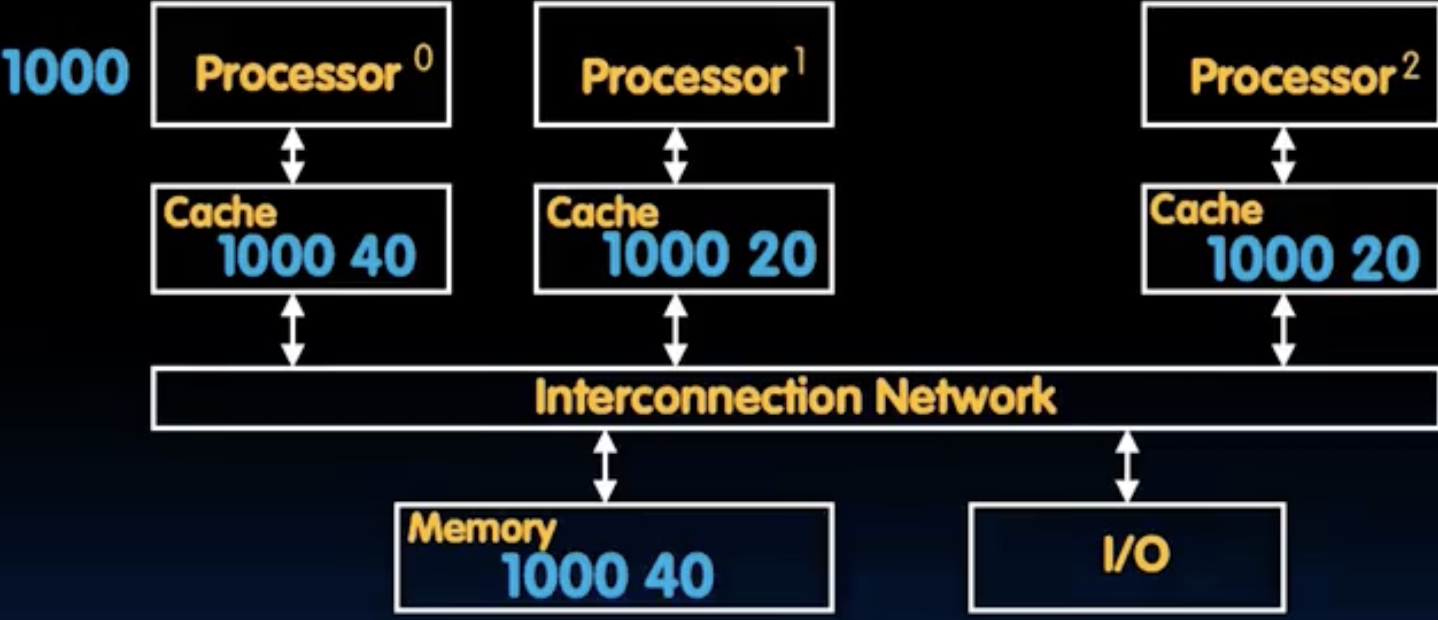
- 如上图所示,现在所有的计算机都采用这种SMP架构,由于内存逐渐变慢,因此我们引入了cache来加速内存访问,当多个CPU有多个独立的cache时,就会出现一些问题。如下图所示,初始M[1000]=20, P1 read M[1000], P2 read M[1000], P0 write M[1000]=40. P1和P2都把M[1000]=20缓存了,然而P0把内存中的M[1000]给改了,P1和P2的cache咋办呢?这就需要Cache Coherency来保证了。
Cache Coherency
- Idea: When any processor has cache miss or write, notify other processors via interconnection network.
- If read, other processors may have copies.
- If write, invalidate other copies.
- 写的具体做法:Write transactions from one processor, other caches “snoop” the common interconnect checking for tags they hold. Invalidate any copies of same address modified in other cache.
Cache中每一个缓存行都可以追踪一个状态,常见的状态有以下几种:
Shared: 该缓存行在多个cache中都有副本,并且都是干净的(没有被修改过)。
Modified: 该缓存行被修改了,并且别的cache中没有副本(被Invalidated了)。且主内存未被更新。
Exclusive: 该缓存行在当前cache中有副本,并且是干净的(没有被修改过)。主内存中的数据与该缓存行一致。
Owner: 该缓存行在当前cache中有副本(干净的),在其他cache可能有副本,但是只有它能change,当它更新时,会通知其他cache更新或者失效。
这个分类倒是不那么重要,回到上一个问题,如何解决P0 write M[1000]=40导致P1和P2的cache失效的问题呢?我们可以直接通过Interconnection Network来通知它们对应缓存行失效,或者直接顺手更新了,这样就保证了cache coherency。
- 之前学习Cache时,有提到过Cache有3种miss,分别是:
- Compulsory Miss : $\quad$ 访问一个地址第一次发生的miss,这个无法避免。通常可以增加block size来缓解。
- Capacity Miss : $\quad$ Cache太小(fully associative),无法容纳所有需要的block,导致miss。通常可以增加cache size来缓解。
- Conflict Miss : $\quad$ Multiple memory locations map to the same cache location. 可以通过增加cache size, 增加associativity来缓解。
- 在学习了Cache Coherency之后,我们还需要考虑一个新的miss,叫Coherence Miss,也被称为communication miss. 3C to 4C 🤣
- 下图展示了一个典型的Coherence Miss. P0需要读写变量X,P1需要读写变量Y,两个变量看似没有关系,然而它们的真实地址可能在同一个缓存行上!因此当P0写X时,Cache0的缓存行更新,同时发出信号通知Cache1对应缓存行失效;反之依然。如此一来,P0和P1就会频繁地发生Coherence Miss,导致性能大幅下降,这就是所谓的False Sharing。
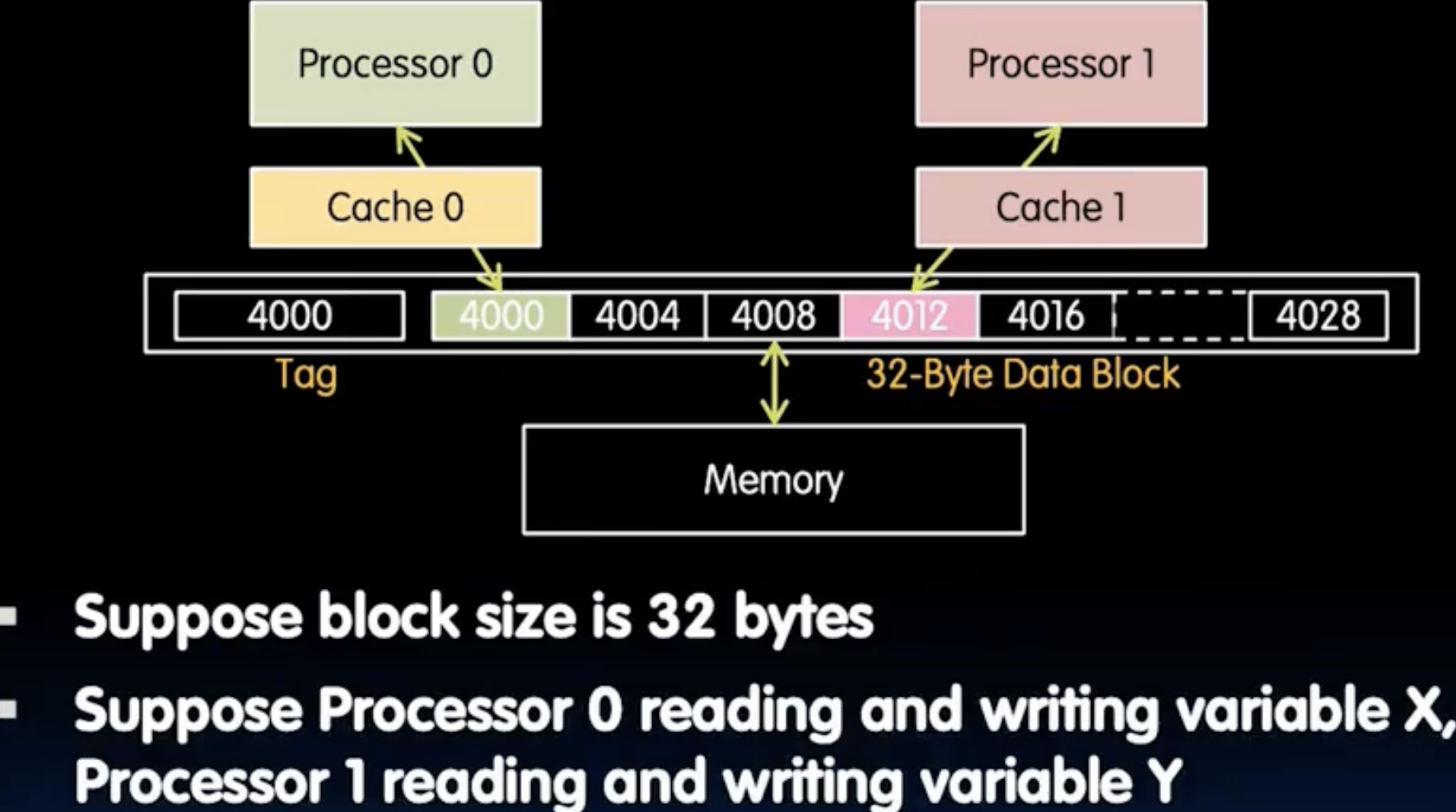
简而言之,Coherence Miss就是多个线程访问了同一个缓存行上的不同位置。由于我们设计的Cache Coherency机制是以缓存行为单位,所以多个线程针对该缓存行反反复复通信更新,导致性能下降。
所以,block size千万不能很大,不然不同线程很容易访问到同一个缓存行上的元素。在并行编程中,Coherence Miss往往占Cache Miss的大头,因此在设计并行算法时,我们需要尽量让线程访问分隔的内存区域,减少False Sharing的发生。
比如之前求π, 我们为每一个线程定义了一个sum[id]来存储局部和,这个做法虽然避免对sum的竞争,但是会导致False Sharing, 因为sum[id]们显然在同一个缓存行上。ai大人说可以通过增加padding来解决这个问题,比如定义一个结构体,每个sum占用一个缓存行的大小(sum[id] + padding = block size),这样不同sum[id]在不同缓存行,就可以避免False Sharing了。
说到这,不知道你有没有疑惑,OS呢,OS怎么不管管它们😡。之前说过OS确实能将不同进程的实际内存分隔开,但是我们现在处理的是多线程问题,在一个主线程下,多个子线程共享一块实际内存区域(只不过各自的map不同),所以冲突问题必然存在。
Lab10
- 本次lab十分有趣,第一部分是熟悉如何用OpenMP写并行程序,第二部分是以一个服务器为例子,引入多进程编程。
Vector Addition
- 下面是原始向量加法代码:
| |
- 下面是两种优化方法,其实在前面都提到过。
| |
如果结合前面提到的False Sharing问题,方法一显然存在很大的性能问题,而方法二由于将一个数组分成了几个连续的块,所以False Sharing的影响就小了很多。测试结果符合预期,方法一在多线程下几乎没有提升,方法二则有将近2x的提升。
事实上,方法二就是#pragma omp parallel for的默认实现方式,所以也可以直接用#pragma omp parallel for来写,OpenMP会帮我们自动分块,非常方便。
Dot Product
- 两个向量点积和向量加法的区别是最后需要将每个位置的结果加起来得到sum,因此会涉及到对共享变量sum的竞争问题。下面是原始代码:
| |
- 原始代码的问题大了去了,#pragma omp critical直接把所有线程都给限制住了,本来我们希望多个线程能同时计算乘法和加法,现在等于没有并行了,性能不升反降了。我们可以直接使用Reduction来解决这个问题,也可以手动实现。
| |
经过测试,原始代码在thread=1的情况性能还是很差,可能是omp critical的开销影响。而两个优化版本在多线程下性能提升明显,有将近7x的加速。
Http Web Server and Multi-processing
- 之前比较简单的lab我都是一笔带过,这次之所以细细展开,主要是这个Http Web Server的实现以及优化非常有意思,让看似鸡肋的
fork()如此nb! - 问题背景:我们设计了一个简单的Http Web Server, 它仅支持GET请求,并且是串行的。然而,如果有多个客户端同时发起请求,假设服务器一次处理需要1s,那么第n个请求就需要等待(n-1)s才能得到响应,用户直接炸毛。所以我们需要将其并行化!
- 一个很朴素的想法,每接受到一个请求,我们就fork一个子进程来处理这个请求,父进程继续监听新的请求,这样就相当于是并行化了。下面是代码实现:
| |
似乎没啥好说的,很朴素的一个想法,然而它的性能提升非常大。在人工设置5s后摇的情况下,3个连续请求的延迟从10008ms干到了43ms!
这个小服务器甚至支持一些花活路由,比如localhost:8000/report, 它会返回调用dotp()的结果,localhost:8000/filter/girl.bmp,它会返回一张经过sobel edge dectection处理过的图片。当然,它的路由设计很简单,我们完全可以自己设计更复杂、更有意思的路由。
除了直接在浏览器中输入路径访问,我们还可以在命令行中使用curl来访问,比如
curl localhost:8000/girl.bmp, 如果你想要快速测试服务器对多请求的延迟,用这个方式无疑最佳。如果你打开files/credit.txt, 你会发现这个Site是由于cs162的作业4魔改过来的,只能说太强🫡
文档中提到,如果子进程刚刚启动,我们就按下Ctrl-C来终止服务器,在父进程死亡后,子进程一般会被init进程收养,成为孤儿进程。等到你想再次启动服务器时会发现8000端口被占用,无法启动(由于设置了5s延迟,子进程不会很快结束),此时你只能用命令行杀死它。在上面的代码中,由于我们设置了
prctl(PR_SET_PDEATHSIG, SIGTERM), 当父进程死亡时,子进程会收到一个SIGTERM信号,释放资源并退出,解决了这个问题。Forking a process to respond to a request is probably not the best parallelism approach – the modern solution is to use a thread pool where the overhead is much lower and you have convenient control over server load.