引
- 本篇将介绍分布式计算框架 MapReduce 和 Spark,…
Amdahl’s Law
- 在我们深入了解 MapReduce 和 Spark 之前,我们先来看看并行计算的一个重要定律:Amdahl’s Law.
- 假设一个程序中有一部分是串行的,另一部分是可以并行化的,那么这个程序的加速比(speedup)就受到串行部分的限制。具体来说,如果串行部分占总运行时间的比例为 S,并行部分占总运行时间为 1-S,那么加速比就是 $$\frac{T}{T*S + \frac{T*(1-S)}{P}}$$即 $$\frac{1}{S + \frac{1-S}{P}}$$其中 T 是原始程序的运行时间,P 是并行化核心数。可以看出,当 P 趋近于无穷大时,加速比的上限是$\frac{1}{S}$,也就是说,串行部分越大,加速比的上限就越小。
- 下图展示了不同并行比例下加速比随核心数增加的变化趋势:
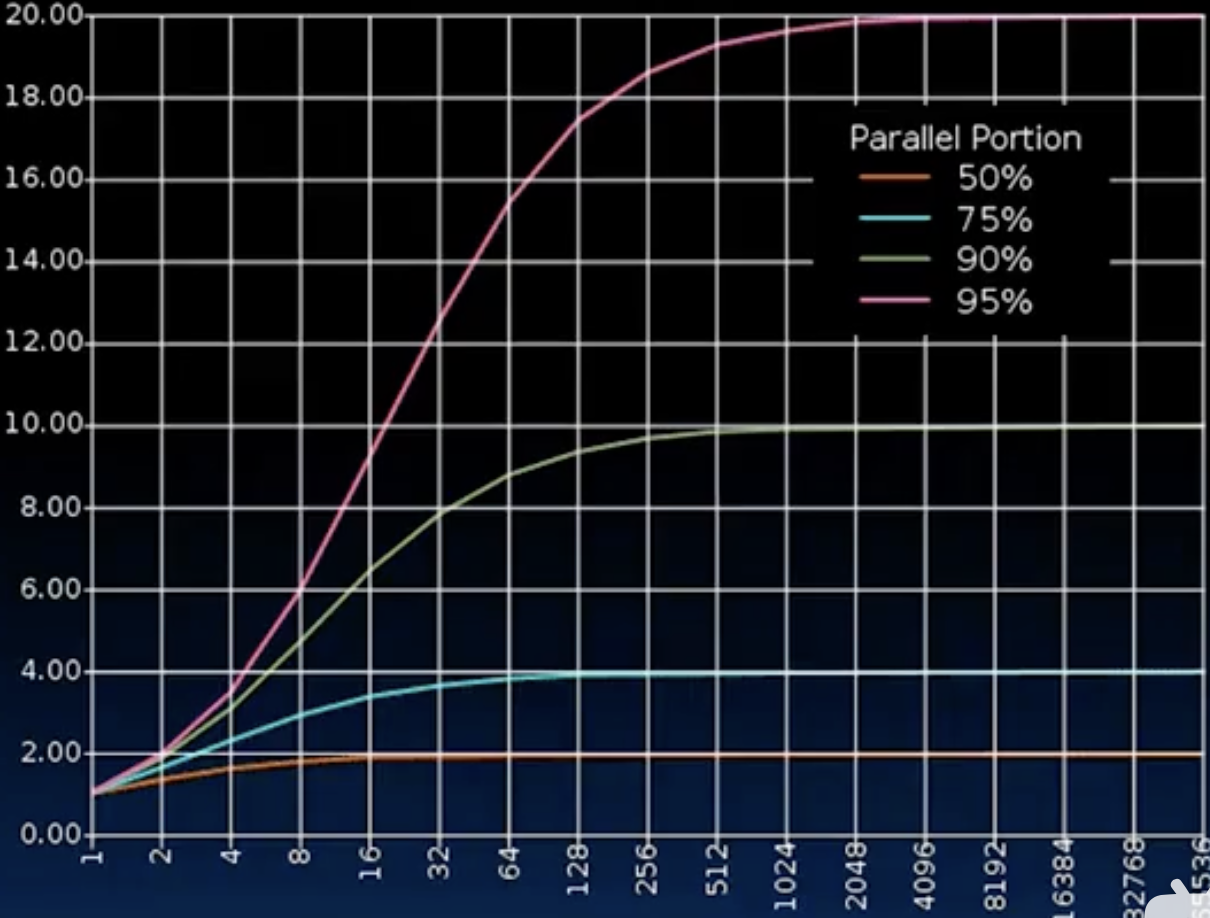
Amdahl’s Law也叫做令人心碎的定律,因为即便并行比例高达95%,使用65536个核心的加速比也只能达到20倍,加速比始终被那5%给限制住,太坏了😇。
所以,在设计算法时,我们应该尽量减少串行部分的比例,或者说,增加并行部分的比例,这样才能更好地利用并行计算资源。
当然,这都是建立在拥有无限多个完美并行核心的假设下,现实中肯定会出现一个比另一个慢,某一个还失败了等情况,我们将在后面解决这些问题。
MapReduce && Spark
- MapReduce 是一种编程模型,用于处理和生成大规模数据集。它的核心思想是将计算任务分为两个阶段:Map 阶段和 Reduce 阶段。在 Map 阶段,输入数据被分成若干个小块,每个小块由一个 Map 函数处理,生成一组中间键值对。在 Reduce 阶段,这些中间键值对被分组,并由一个 Reduce 函数处理,生成最终的输出结果。其中,Map 函数和 Reduce 函数都是用户自定义的,可以根据具体的计算任务进行编写。在进入Reduce阶段之前,需要有一步Shuffle的过程,将Map阶段输出的中间键值对按照键进行分组,以便Reduce阶段能够正确地处理这些数据。
- 举一个简单的例子,假设有一台多核机器,我们有两个文本句子,一个是Me Me Yep,一个是Me Yep Yep。我们想要统计每一个单词的频率,首先将两个句子分派给两个cpu核进行Map阶段的处理,得到中间结果:(Me, 2), (Yep, 1) 和 (Me, 1), (Yep, 2)。然后进行Shuffle阶段,将中间结果发送给两个cpu核,第一个得到(Me, 2),(Me, 1),第二个得到(Yep, 1),(Yep, 2)。最后,两个cpu核分别进行Reduce即可。
当然,现实中MapReduce不仅仅能够让多核心协同工作,还可以让多台机器协同工作,甚至是跨数据中心的协同工作。MapReduce的设计理念就是将计算任务分解为小块,然后分发给不同的计算节点进行处理,最后再将结果汇总起来。这种设计理念使得MapReduce能够处理大规模的数据集,并且具有很好的可扩展性和容错性。
MapReduce的过程并不是Map -> Reduce这么简单,中间可能有很多步Map,Reduce之后可能还有Map … ,可以自由组合,MapReduce能高效调度计算节点完成这些步骤。
Shuffle阶段如何分组呢?通常是根据Hash(Key) % NumReduceNodes来决定每一个中间键值对应该发送给哪一个Reduce节点,这样可以保证相同的Key会被发送到同一个Reduce节点进行处理。
2006年,Doug Cutting 等人根据 Google 的论文,用 Java 语言实现了 MapReduce 框架,与其他组件(比如HDFS分布式文件系统)共同形成了 Hadoop。
由于Hadoop的MapReduce框架是基于磁盘的,数据在计算之后需要写回磁盘,这样会导致大量的I/O操作,严重影响性能。为了解决这个问题,Apache Spark应运而生,它是一个基于内存的分布式计算框架,可以大大提高计算速度。Spark的核心是RDD(Resilient Distributed Dataset),它是一种不可变的分布式数据集,可以在内存中进行计算,从而减少了I/O操作,提高了性能。
在分布式系统中,访问别的机器内存的时间小于读/写本地磁盘时间,在理想情况下,如果集群所有节点的内存总量足够大,Spark 可以把中间结果尽量缓存在内存中,避免 MapReduce 那样反复读写磁盘。“内存”的访问速度比磁盘快几个数量级,这正是 Spark 在迭代计算中能获得数十倍性能提升的根本原因。
Lab11
- Lab11 带我们熟悉Spark工具的应用,使用
flatMap,map,reduceByKey,sortByKey,distinct等函数来实现单词计数,每个单词在多少个文档中出现过、在文档中出现的位置,出现频率最高的单词等小任务。 - 当然了,由于没有分布式集群给我们使用,所以该lab是在本地机器上开了local[8]模式,模拟了8个cpu核的分布式计算环境。Spark的一个非常好的地方是,写完了环境配置代码后,具体逻辑部分的代码非常简单,就几个函数的组合,Spark的函数式编程风格让我们可以专注于业务逻辑,而不用关心底层的分布式计算细节。
- 文档提到可以到Project Gutenberg下载你喜欢的文本进行测试,如果下载时遇到网络问题,可以尝试直接在命令行下载 , e.g.
wget www.gutenberg.org/ebooks/215.txt.utf-8.
本地运行需要自行下载Spark和Hadoop, 对于archlinux用户,二者均可通过yay安装,其中Hadoop请务必安装Hadoop-bin预编译版本,源码编译时间过长,且容易出错。
The rest content of CS61c
- 剩下几节课的内容都是偏通识介绍,我就偷个懒不记了,请自行观看视频。
- 重点包括:
- 云计算,data center,分布式
- ECC, Hamming Code, Parity Bit
- RAID 4 and RAID 5
- 后面也许会写一篇关于Project 4的文章。
Project4 – Numc
- 可以参考这篇知乎对Project4的评价,总体来说与我的感受差不多。
- 前三个Task需要你查找不少Python C API的文档,有点坐牢的感觉,很多函数官方文档甚至不给个example ?
- dumpy是不提供的,网上也没有,你可以让ai帮你把numpy包装成dumpy,注意矩阵初始化时不能使用numpy.random.rand( ), 因为在matrix.c中我们是用c的rand( )函数生成随机矩阵的,二者并不一样。为了保证正确性测试,请直接将numc.Matrix初始化的矩阵元素复制到dumpy的初始化矩阵。
- 经过我手搓证实,1D矩阵的shape处理确实恶心,各种edge test很烦,所以文档也提到可以忽略它的edge test,保证2D矩阵的正确性即可。
- 优化部分,循环展开和SIMD指令疑似没有什么效果,i-j-k -> i-k-j交换顺序能提高2-3倍,OpenMP多线程能提高3-4倍左右,pow使用快速幂算法能提高2-3倍,最终优化后能达到numpy的$\frac{1}{4}$左右的性能。当然,性能具体提升多少和测试矩阵大小,形状,种子,参数等都有关系。