引
终于来到了本次课程的最后一讲。在前四讲中,我们介绍了欧氏空间中扩散模型的基本原理、训练方法、神经网络架构以及一些常用的数学工具。核心假设是:数据可以用一个向量在$R^d$空间中表示,且不同数据之间是连续、光滑的。这正是 flow matching 和 score matching 能够借助微分方程建模的基础。但在实际应用中,很多数据并非天生处于连续空间——例如文本生成、蛋白质组成等场景,数据是由一个个离散 token 构成的序列。我们无法得到一个连续的场,让这些 token 在其中平滑流动。因此,需要一套专门处理离散数据的生成框架,这就是 Discrete Diffusion Models。
从这一设定出发,ODE、SDE 等连续微分方程工具将不再适用。取而代之的是连续时间马尔可夫链(Continuous-Time Markov Chains, CTMCs)。接下来,我们将介绍 CTMCs 的基本概念与原理,并展示如何用它构建一个 LLM 式的离散生成模型。
温馨提示:本讲对应的课程视频我认为老师讲的不太好,有部分内容讲得比较模糊?也跳了不少,所以还是推荐大家认真看一遍note。
Continuous-Time Markov chain (CTMC) models
- 首先,对于离散数据,我们定义一个字母表 $vocabulary = {v_1, v_2, \cdots, v_V}$, 其中每一个$v_i$ 都是一个独立的token,于是我们可以定义一个离散空间 $ S = V^d $, 其中d是序列长度,对于$x \in S$, $x = (x_1, x_2, \cdots, x_d)$, 其中每一个$x_i$ 都是vocabulary中的一个token。此时,你就应该能明白为什么ODE,SDE等连续微分方程在这里不起作用了吧。
补充一下Markov process的概念,马尔可夫过程是一个无记忆的过程,即未来的状态只与当前状态有关,而与过去的状态无关。假设存在一个随机过程$X_t \in S$, $t \in (0,1)$, 满足:
$$ \underbrace{p(X_{t+h} \mid X_t, X_{t_1}, \cdots, X_{t_k})}_{\text{prob. of future given present and past}} = \underbrace{p(X_{t+h} \mid X_t)}_{\text{prob. of future given present}} \qquad (\forall\, 0 < h,\ 0 \leq t_1 < t_2 < \cdots < t_k < t) $$需要知道的是,ODE和SDE都是Markov process,因为由公式可知,下一个时间点的概率分布可以由当前的概率分布、当前的向量场、当前的的噪声和score函数唯一确定,而与之前的状态无关。对于离散空间的Markov process, 我们称之为Markov chain, 故命名为Continuous-Time Markov Chain (CTMC)。
我们称$p(X_{t+h}|X_t)$为transition probabilities, 由马尔可夫性质知道,一个CTMC过程完全由$X_0 \sim p_0$和transition probabilities唯一确定。因此,后面提到CTMC,我们默认就是transition probabilities了。
- 此时,有一个很严重的问题:在欧式空间中,对于两个数据点,我们可以通过一条连续的路径将它们连接起来,即二者坐标作差得到的向量就是当前最优的路径方向;但是在上述定义的离散空间中,如何衡量两个点之间的距离呢?又如何定义一条从A到B的路径呢?对此,我们定义一个rate matrix $Q_t(y|x) \in R$, which effectively summarizes the rate of jumping (or switching) from state $x \in S$ to state $y \in S$ at time t. 这个定义和欧式空间中的是有本质区别的,欧式空间中我们是通过一个方向场来从A到B的,而在离散空间,我们不得不一步到位,直接从A突变到B了。
此外,这个rate matrix还必须满足如下两个性质:
(1) $\quad $ Outgoing rates are positive: $Q_t(y|x) \geq 0$ $\quad$ for all $x \neq y$.
(2) $\quad $ Rate staying equals negative outgoing rate: $Q_t(x|x) = -\sum_{y \neq x} Q_t(y|x)$ $\quad$ for any x.
这两个性质说明,从x变化到其他状态的rate必然是非负的,如果不可能switch到某个状态,那么Q就是0;同时,对于x状态,它自己的rate必然和其他状态switch到x的rate之和抵消。故对角线上的元素是非正的,非对角线元素是非负的。
- 有了rate matrix,我们希望它能发挥和vector field在欧式空间中类似的作用, 有如下奇妙定义: $$ \left. \frac{d}{dh} p_{t+h|t}(X_{t+h} = y \mid X_t = x) \right|_{h=0} = Q_t(y \mid x), \qquad \forall x, y \in S,\ 0 \le t $$ 直觉理解左侧是从x到y的transition probability的瞬时变化率,似乎和rate matrix有点符合哈,但是我们还需要证明一下这个定义是符合上述两个性质的.
证明如下:
对于第一条,当h=0时,显然$X_t$来不及变化,所以如果$y \neq x$, 那么此时概率为0,而当h>0时,概率必然是非负的,所以说明在0处导数非负。
对于第二条,推导如下:
$$ \sum_{y \neq x} \frac{d}{dh} p(X_{t+h} = y \mid X_t = x) \big|_{h=0} = \sum_{y \neq x} Q_t(y \mid x) = \frac{d}{dh} \left(1 - p(X_{t+h} = x \mid X_t = x)\right) \big|_{h=0} = - Q_t(x \mid x) $$- ok,由上面的定义我们可以知道,对于一个CTMC过程,我们一定能找到一个满足那两条性质的rate matrix(直接求导即可);反过来,如果我们有一个满足那两条性质的rate matrix,是否能找到一个CTMC过程使得那个公式成立呢?如果能找到,是否是唯一的呢?答案是肯定的,证明略😆,在note中的Section C 自行阅读。这种唯一存在性质让我们可以先用一个神经网络预测出$Q_t(y|x)$,然后必然会有一个唯一的Markov chain 与之对应。
note中的Example 34还是不错的,结合图像可以生动理解rate matrix的含义。
Simulation of CTMC
- ok,现在让我们尝试用上述定义的rate matrix来模拟一个CTMC过程。令h>0是一个时间步,$p_{init}$是S的一个分布,在之前的ODE和SDE中,我们通常使用高斯分布作为初始分布,但是在离散空间中,不存在什么高斯分布,所以我们使用$p_{init} = Uniform(S)$, 即在S上均匀分布。采样$X_0 \sim p_{init}$, 对于每一个时间步,有$X_{t+h} \sim p_{t+h|t}(\cdot | X_t)$. 于是,只要我们知道$p_{t+h|t}(\cdot | X_t)$, 即transition probabilities, 就可以模拟了。但是对于大多数CTMC来说,transition probabilities是没有closed-form solution的,所以我们能用的只有rate matrix了, 由于rate matrix反应了transition probabilities的瞬时变化率,所以我们可以使用泰勒展开来近似transition probabilities:
其中$R_t(h)$是高阶误差项,当h很小时可以忽略。
$$ p_{t+h|t}(X_{t+h} = y \mid X_t = x) \approx \mathbf{1}_{y=x} + h Q_t(y \mid x) =: \tilde{p}_{t+h|t}(y \mid x) $$于是,我们对S中所有的y进行上式计算得到$p_{t+h|t}(\cdot | x)$, $X_{t+h}$将按照不同x的概率进行采样。
$$ X_{t+h} \sim \tilde{p}_{t+h|t}(\cdot \mid x) = \big( \mathbf{1}_{y=x} + h Q_t(y \mid x) \big)_{y \in S} $$这里有一个问题哈,就是我们说transition probabilities没有闭式解,但是Q应该也没有闭式解啊,所以上面的Q从哪里来呢?从后面看,这个Q应该是用神经网络预测出来的?这里其实就是告诉你可以通过变化公式来用Q进行sample next state。
CTMC model
- 现在,让我们用神经网络来参数化一个CTMC过程。A CTMC model (or discrete diffusion model) is given by an initial distribution $p_{init}$ over S and a neural network $Q_t^{\theta}$ with parameters θ such that for every input $x \in S$ the model returns a single column of the rate matrix : $$x \rightarrow \{ Q_t^{\theta}(y|x) \}_{y \in S}$$ 如此一来,我们就可以用神经网络预测出an entire column, 而这个正是上面写的next state的公式中需要的。
- 千万不要沾沾自喜,我们看似构建了从state to next state的模型,但是需要知道的是S是一个非常非常非常大的空间,所以上面的y的可能取值是$V^d$个,指数爆炸,没有一个计算机的内存能装下这个。于是,我们需要对这个state -> next state的过程进行一些压缩和限制,一个比较好的想法是factorized(绝大多数CTMC模型都采用这种方法),即每次最多改变一个token,这样就大大减少了next state的可能取值,也就不用存一个巨大的column了。
A factorized CTMC model is given by a CTMC model $Q_\theta^t$ such that for all $y = (y_1, \ldots, y_d), x = (x_1, \ldots, x_d) \in S = V^d$ $\qquad$ it holds :
\[ Q_\theta^t(y \mid x) = 0 \quad \text{whenever } y_i \neq x_i \text{ for more than one position } i. \]于是,我们可以把那些和x最多有一个token不同的y叫做Neighbors N(x) of x,故上面的公式可以改写成:
$$ x \rightarrow \left\{ Q^\theta_t(y \mid x) \right\}_{y \in N(x)} = \begin{pmatrix} Q^\theta_t(v_{1}, 1 \mid x) & \cdots & Q^\theta_t(v_{V}, 1 \mid x) \\ & \cdots & \\ Q^\theta_t(v_{1}, d \mid x) & \cdots & Q^\theta_t(v_{V}, d \mid x) \end{pmatrix} $$其中,$Q^\theta_t(v_i, j \mid x)$表示对于x的第j个token,我们把它变成vacabulary中的第i个token的rate, 得到$y = (x_1, \cdots, x_{j-1}, v_i, x_{j+1}, \cdots, x_d)$. 虽然是用神经网络预测的Q,但是我们仍然需要满足: (1) $\qquad$ $Q^\theta_t(v_i, j \mid x) \geq 0$ $\quad$ if $v_i \neq x_j$
(2) $\qquad$ $Q^\theta_t(x_j, j \mid x) = -\sum_{v \neq x_j} Q^\theta_t(v, j \mid x)$ $\quad$
很容易发现,使用factorized 后的next state的维度是$d \times V$, 和d,V都是成正比的,远远优于之前的$V^d$!!
需要注意的是,在上面的定义中,我们标注了两条需要满足的性质,在实际网络构架中,我们可以使用transformer作为骨干,在输出d x V的矩阵后,使用一些类似ReLU或softmax的激活函数满足第一条,然后再计算没行中not switch的rate来满足第二条。
Simulating a CTMC model
- 现在,我们已经有了一个用Q进行simulation的公式了,有了用$\theta$参数化的Q了,并且使用factorized的方式来限制next state的维度,于是我们可以对这个神经网络模型进行simulatioin了,伪代码如下:

- 不知道你有没有发现一个问题,我们之前不是说,我们只考虑Neighbors of x吗?也就是说每一步,我们最多有一个token的变化,但是在上面的代码中,我们内层对d进行循环,这样就可能出现有多个token变化的情况了。如果不考虑它违反了neighbor原则,从直观上理解这个反而是合理的,毕竟每一个时间步,我们肯定是希望每一个位置的token都有机会发生变化,不可能说固定哪个token变化吧,就算是固定了第一步变化第一个token,第二部变化第二个token,。。。,那么每一个时间步都最多变化一个token,十分低效啊,可能需要很多很多时间步才能从$x_0$到最终目标z。所以,在考虑到所有token都有机会变化(这个也是discrete difussion model 和 gpt类auto regressive model的一个重大区别,后者只能一个一个确定)和提高每一个时间步的计算效率,这个伪代码很合理。
note中提到 This approximation agrees with the full CTMC Euler step up to first order in h, but allows for a O(h2) probability of simultaneous updates to multiple tokens. 也就是说,上面的伪代码确实违反了neighbor原则,但是误差是二阶的,可以接受。 为什么是二阶的呢?
对于一个token来说,如果更新的$v \neq x$, 它的概率是$h q_j(v)$. 当有两个token同时发生变化时,概率就是$h^2 q_j(v) q_{i}(v_1)$, 其中q就是Q,默认是一个常数,所以这个概率就是$O(h^2)$的。在一阶精度可以接受,其实就是说误差都是二阶及以上。
Training CTMC models
- ok,现在我们已经有了一个可以参数化的CTMC模型了,并且学会了如何进行simulation了,如何训练这个模型呢?下面展示了训练的三个步骤:
The principles are the same as for flow matching:
- We construct a probability path interpolating between noise and data.
- We derive a conditional rate matrix and marginal rate matrix.
- We learn the marginal rate matrix in a simulation-free manner.
Our goal is to train the CTMC model $Q_\theta^t$ such that
\[ X_0 \sim p_{\text{init}}, \quad X_t \text{ CTMC of } Q_\theta^t \quad \Rightarrow \quad X_1 \sim p_{\text{data}} \]其中$p_{data}$是我们想要生成的离散数据的分布,比如互联网上的文本数据,但是显然我们不可能对$p_{data}$有一个表达式,所以我们在训练的时候逐个采样具体的数据点z。所以,你应该意识到,这个训练思路和之前的flow matching几乎一样,我们只是把中间的迭代过程从ODE变成了CTMC而已。
Conditional and Marginal Probability Path
- 我们定义$\delta_z(x)$ : 当$x=z$时为1,否则为0.(注意它是一个分布,只不过所有的概率质量都集中到了一个点上)故 (discrete) conditional probability path is given by a set of distributions $p_t(x \mid z)$ for $x, z \in S$ and $0 \le t \le 1$ such that \[ p_0(\cdot \mid z) = p_{\text{init}}, \qquad p_1(\cdot \mid z) = \delta_z. \] 故 (discrete) marginal probability path is then given by \[ p_t(x) = \sum_{z \in S} p_t(x \mid z) \, p_{\text{data}}(z) \] 简单带入0和1可知: $p_0(x) = p_{init}$, $p_1(x) = p_{data}$.
Note中定义:Factorized mixture path (independent noising per token)
Let $S = V^d$ and let $p_{\text{init}}(x) = \prod_{j=1}^d p_{\text{init}}^{(j)}(x_j)$ be a factorized initial distribution. Fix a scheduler $0 \le \kappa_t \le 1$ such that $\kappa_0 = 0$, $\kappa_1 = 1$ with $\frac{d}{dt} \kappa_t \ge 0$. Define the conditional path by
\[ p_t(x \mid z) = \prod_{j=1}^d \left( (1 - \kappa_t) \, p_{\text{init}}^{(j)}(x_j) + \kappa_t \, \delta_{z_j}(x_j) \right). \]这个公式是将x的d个token完全独立进行变化的结果,与我们前面提到的discrete diffusion model中每一个token的生成不遵循顺序,而是同时进行的思想是一致的。不过这里命名为Factorized mixture path, 这里的factorized应该是指每个token的变化都是独立的,和之前factorized CTMC model中每次最多改变一个token的factorized含义是不同的。
它和我们之前提到的Gaussian path的区别在于,Gaussian path是以一个概率分布为主体,从init状态,不断变形移动,最终变成data distribution; 而Factorized mixture path是有很多不同的state点z,我们从一个init点出发,每一步都根据概率选择跳转到哪个z上去,最终希望能跳到data distribution上去。总而言之,前者是一个分布连续变形过程,后者是一个离散随机跳转过程。 ps: 如果你能意识到这个点,那么说明你对整个课程的理解很不错哈🥰
Conditional and Marginal Rate Matrix
we call it a conditional rate matrix if
$$ X_0 \sim p_{\text{init}}, \quad X_t \text{ CTMC of } Q_t^z \quad \Rightarrow \quad X_t \sim p_t(\cdot \mid z) $$先直接给出marginal rate matrix的定义:
Theorem 36 (Discrete marginalization trick). The marginal rate matrix defined by
$$ Q_t(y \mid x) = \sum_{z \in S} Q_t^z(y \mid x) \, \frac{p_t(x \mid z) \, p_{\text{data}}(z)}{p_t(x)} = \sum_{z \in S} Q_t^z(y \mid x) \, p_{1|t}(z \mid x) $$where
$$ p_{1|t}(z \mid x) := \frac{p_t(x \mid z) \, p_{\text{data}}(z)}{p_t(x)} $$is a valid rate matrix and fulfills the following condition:
$$ X_0 \sim p_{\text{init}}, \quad X_t \text{ CTMC of } Q_t \quad \Rightarrow \quad X_t \sim p_t. $$- 这里的道理和之前flow matching中的marginalization trick是一样的,就是这个公式看起来合理,但是需要证明它正确性,我们需要证明一个CTMC过程的基本等式 —— Kolmogorov Forward equation。
Kolmogorov Forward Equation (KFE).
Let $p_t$ be a set of distributions on $S$ for every $0 \le t \le 1$. Further, let $X_t$ be a CTMC with matrix $Q_t$ and initial distribution $p_0$. Then $X_t \sim p_t$ for all $0 \le t \le 1$ if and only if the Kolmogorov Forward Equation (KFE) holds:
$$ \frac{d}{dt} p_t(x) = \sum_{y \in S} Q_t(x \mid y) \, p_t(y). $$于是,我们只要证明先前定义的marginal rate matrix满足KFE就可以了。
有:
$$ \begin{aligned} \frac{d}{dt} p_t(x) &= \frac{d}{dt} \sum_{z \in S} p_t(x \mid z) \, p_{\text{data}}(z) \\ &= \sum_{z \in S} \frac{d}{dt} p_t(x \mid z) \, p_{\text{data}}(z) \\ &= \sum_{z \in S} \sum_{y \in S} Q_t^z(x \mid y) \, p_t(y \mid z) \, p_{\text{data}}(z) \\ &= \sum_{y \in S} \left( \sum_{z \in S} Q_t^z(x \mid y) \, \frac{p_t(y \mid z) \, p_{\text{data}}(z)}{p_t(y)} \right) p_t(y) \\ &= \sum_{y \in S} Q_t(x \mid y) \, p_t(y) \end{aligned} $$上面的证明用到了$\frac{d}{dt} p_t(x \mid z) = \sum_{y \in S} Q_t^z(x \mid y) , p_t(y \mid z)$, 由于一个conditional path($target=z$)必然也满足KFE,对比KFE的定义可知这个就是它的conditional版本,所以这个等式是成立的。这个证明过程基本和flow matching中的一样。
不过,还有一个问题,就是为什么满足KFE就说明这个CTMC过程的分布是$p_t$呢(或者说二者等价),在flow matching中,我们似乎没有严谨证明这个事,只是直观理解。下面我们来证明一下:
首先证明KFE是必要条件: To show that the KFE is necessary, assume that $p_t(x)$ are the true marginals of the CTMC, i.e. $X_t \sim p_t$ for every $0 \le t \le 1$. Then we can compute:
$$ \begin{aligned} \frac{d}{dt} p_t(x) &\stackrel{\text{(i)}}{=} \left. \frac{d}{dh} \right|_{h=0} p_{t+h}(x) \\ &\stackrel{\text{(ii)}}{=} \left. \frac{d}{dh} \right|_{h=0} \sum_{y} p_{t+h|t}(x \mid y) \, p_t(y) \\ &\stackrel{\text{(iii)}}{=} \sum_{y} \left. \frac{d}{dh} \right|_{h=0} p_{t+h|t}(x \mid y) \, p_t(y) \\ &\stackrel{\text{(iv)}}{=} \sum_{y} Q_t(x \mid y) \, p_t(y) \end{aligned} $$where in (i) we simply use a time offset, in (ii) we use the definition of the transition probabilities, in (iii) we swap the sum and derivative, and in (iv) we use the definition of the rate matrix.
接下来证明KFE是充分条件: To show that the KFE is sufficient, we can rewrite the KFE in matrix form:
$$\frac{d}{dt} p_t = Q_t \, p_t$$Note that the above is a linear ODE over vector space $R^S$. Its initial condition is fixed by $p_0$ as stated in the theorem.
$p_t$就是所有S中可能点x的概率分布(可以看成一个vector),而Q就是S中所有y到x的rate matrix的大矩阵,对于t时刻,右边直接就算出来了,所以这个ODE其实就是一个一阶线性微分方程,在初始$p_0$给定的条件下,这个ODE解出来的$p_t$必然是唯一的。
需要注意的是,之前定义中的等价的两个事件是:如果$p_t$是某个CTMC的边际分布$<=>$ $p_t$满足KFE。当前我们只证明了如果$p_t$满足KFE,那么这个$p_t$一定是唯一的,似乎没有说明它是某个CTMC的边际分布啊?产生这个疑惑的原因是,由于公式中掺杂了Q,导致我们无法直接看到一个CTMC的过程, 下面是我的一个理解:
如果$p_t$是一个CTMC过程的分布,则:
$$ p_{t+h}(x) = (p_{t+h|t}(x \mid y) \, p_t(y))_{y \in S} $$求导得到:
$$ \frac{d}{dh} p_{t+h}(x) \big|_{h=0} = \left( \frac{d}{dh} p_{t+h|t}(x \mid y) \big|_{h=0} \, p_t(y) \right)_{y \in S} = (Q_t(x \mid y) \, p_t(y))_{y \in S} $$而$\frac{d}{dh} p_{t+h}(x) \big|_{h=0} = \frac{d}{dt} p_t(x)$, 替换得到:
$$\frac{d}{dt} p_t(x) = \sum_{y \in S} Q_t(x \mid y) \, p_t(y)$$而这个式子我们已经有了,再积分回去即能看出$p_t$是满足CTMC的定义了。
然而note的证明更绝:
设 $q_t$ 为 CTMC 的真正边际分布。
由必要性(之前证明过的部分),我们知道 $q_t$ 一定满足 KFE:
我们又构造了一个 $p_t$,并且它也满足:
$$ \frac{d}{dt} p_t = Q_t p_t $$由 ODE 解的唯一性(给定 $p_0$ 相同),所以:
$$ p_t = q_t $$因此 $p_t$ 就是那个 CTMC 的边际分布。 太美妙了,我的证明是🐷,之所以会捣鼓出这个🐷证明是因为我一开始没看到note中那个绝妙的证明😭
- ok,现在我们已经搞定了Conditional and Marginal Rate Matrix了,接下来我们以factorized mixture path为例子计算一下它的conditional rate matrix。
Example 37 (Conditional rate matrix for factorized mixture path). Set $\frac{d}{dt}\kappa_t = \dot{\kappa}_t$. The factorized mixture path has a factorized conditional rate matrix given by
$$ Q_t^z(y \mid x) = \bigl( Q_t^z(v_i, j \mid x_j) \bigr)_{v_i, j} $$$$ Q_t^z(v_i, j \mid x_j) = \frac{\dot{\kappa}_t}{1-\kappa_t} \bigl( \delta_{z_j}(v_i) - \delta_{x_j}(v_i) \bigr) = \frac{\dot{\kappa}_t}{1-\kappa_t} \begin{cases} 0 & \text{if } x_j = z_j, \\[4pt] 1 & \text{if } v_i = z_j, \; x_j \neq z_j, \\[4pt] 0 & \text{if } v_i \neq z_j, \; x_j \neq z_j, v_i \neq x_i, \\[4pt] -1 & \text{if } v_i = x_j, \; x_j \neq z_j. \end{cases} $$上面这个公式就非常美妙,我们最终的目标是每一个$x_i$能变成$z_i$, 所以可以看到只有当$v_i = z_i \text{ and }x_j \neq z_j$时,rate是1;其他情况下,rate要么是0,要么是-1.
如何证明这个公式就是factorized mixture path的conditional rate matrix呢?根据前面的结论,我们需要证明它满足KFE等式,由于factorized mixture path每一个token都是独立的,所以我们不妨就考虑一个token的情况:
$$ \begin{aligned} \frac{d}{dt} p_t(x \mid z) &\stackrel{\text{(i)}}{=} \frac{d}{dt} \left[ (1-\kappa_t) p_{\text{init}}(x) + \kappa_t \delta_z(x) \right] \\ &\stackrel{\text{(ii)}}{=} \dot{\kappa}_t \delta_z(x) - \dot{\kappa}_t p_{\text{init}}(x) \\ &\stackrel{\text{(iii)}}{=} \frac{\dot{\kappa}_t}{1-\kappa_t} \left( \delta_z(x) - \left[ (1-\kappa_t) p_{\text{init}}(x) + \kappa_t \delta_z(x) \right] \right) \\ &\stackrel{\text{(iv)}}{=} \frac{\dot{\kappa}_t}{1-\kappa_t} \left( \delta_z(x) - p_t(x \mid z) \right) \\ &\stackrel{\text{(v)}}{=} \frac{\dot{\kappa}_t}{1-\kappa_t} \delta_z(x) \left( 1 - p_t(x \mid z) \right) + \frac{\dot{\kappa}_t}{1-\kappa_t} (\delta_z(x)-1) p_t(x \mid z) \\ &\stackrel{\text{(vi)}}{=} \frac{\dot{\kappa}_t}{1-\kappa_t} \delta_z(x) \sum_{y \neq x} p_t(y \mid z)+ \frac{\dot{\kappa}_t}{1-\kappa_t} (\delta_z(x)-1) p_t(x \mid z)\\ &\stackrel{\text{(vii)}}{=} \sum_{y \neq x} Q_t^z(x \mid y) \, p_t(y \mid z) + Q_t^z(x \mid x) \, p_t(x \mid z) \\ &\stackrel{\text{(viii)}}{=} \sum_{y \in S} Q_t^z(x \mid y) \, p_t(y \mid z) \end{aligned} $$(i) uses the definition of the factorized mixture path for $d=1$
(ii) is obtained by taking derivatives and setting $\frac{d}{dt}\kappa_t = \dot{\kappa}_t$
(iii) follows by simple algebra
(iv) by the definition of the factorized mixture path
(v) by simple algebra
(vi) follows from the fact that $\sum_{y \in S} p_t(y \mid z) = 1$
(vii) by the definition of the rate matrix, and (viii) by simple algebra.
其中需要关注的步骤是(vii),这一步我们用到了先前对factorized mixture conditional rate matrix的定义,对于第一项$y \neq x$,$Q_t^z(x \mid y)$, 只有当$x=z$时跳转,rate=1;当$x\neq z$时,不跳转,rate=0. 对于第二项$y = x$, $Q_t^z(x \mid x)$, 当$x=z$时,不跳转,rate=0;当$x \neq z$时,rate=-1. 每一种结果都和$\delta_z(x)$,$\delta_z(x) - 1$是一致的,所以(vii)是ok的。 于是,我们证明了这个定义下的conditional rate matrix满足KFE等式,所以它就是该factorized mixture path的conditional rate matrix了。
Learning the Marginal Rate Matrix
ok,现在我们已经有了factorized mixture path的conditional rate matrix了,而这个path正是当前绝大多数discrete diffusion/flow matching model采用的,所以我们接下来都将以这个path为例子来说明如何学习它的marginal rate matrix.
首先,我们需要根据之前的marginalization trick的定义来计算一下它的marginal rate matrix,首先给出结论:
Theorem 38 (Marginalization trick for factorized mixture path). The marginal rate matrix of the factorized mixture path is factorized and has the form
$$ Q_t(v_i, j \mid x) = \frac{\dot{\kappa}_t }{1 - {\kappa}_t}\left( p_{1|t}(z_j = v_i \mid x) - \delta_{x_j}(v_i) \right) $$where $p_{1|t}(z_j = v_i \mid x)$ is the conditional probability of the $j$-th position ($j$-th token in the sequence) being equal to $v_i$ given the full noisy sequence $x$. 它表示在时刻t,给定当前状态x,token位置j变成v_i的rate。
如何证明这个结论呢?
$$ \begin{aligned} Q_t(v_i, j \mid x) &= \sum_{z \in S} Q_t^z(v_i, j \mid x) \, p_{1|t}(z \mid x)\\ &\stackrel{\text{(i)}}{=} \sum_{z \in S} \frac{\dot{\kappa}_t}{1-\kappa_t} \bigl( \delta_{z_j}(v_i) - \delta_{x_j}(v_i) \bigr) \, p_{1|t}(z \mid x)\\ &\stackrel{\text{(ii)}}{=} \frac{\dot{\kappa}_t}{1-\kappa_t} \left( \sum_{z \in S} \delta_{z_j}(v_i) \, p_{1|t}(z \mid x) - \delta_{x_j}(v_i) \right)\\ &\stackrel{\text{(iii)}}{=} \frac{\dot{\kappa}_t}{1-\kappa_t} \left( p_{1|t}(z_j = v_i \mid x) - \delta_{x_j}(v_i) \right) \end{aligned} $$- 至此,我们已经得到了factorized mixture path的marginal rate matrix了,即: $$ Q_t(v_i, j \mid x) = \frac{\dot{\kappa}_t }{1 - {\kappa}_t}\left( p_{1|t}(z_j = v_i \mid x) - \delta_{x_j}(v_i) \right) $$ 对于这个式子,哪个部分是需要我们训练的呢?首先${\kappa_t}$是一个scheduler,是我们人为设定的,括号中的第二项$\delta_{x_j}(v_i)$也是一个常数,唯一一个无法知道的是括号中的第一项$p_{1|t}(z_j = v_i \mid x)$, 这是一个条件概率,由于我们不知道z,也不知道它的分布,所以无法直接计算它,所以它就是我们需要训练的部分了!

- ok,现在万事具备,可以开始训练了,但是别急,我们先来看看$p_{init}$的另一种选择,之前我们说过,离散空间中不存在高斯分布,所以我们使用了S每一个点的均匀采样作为初始分布,但是这个方法包含了一些随机信息,有没有更简答的初始化呢?有的,有的:
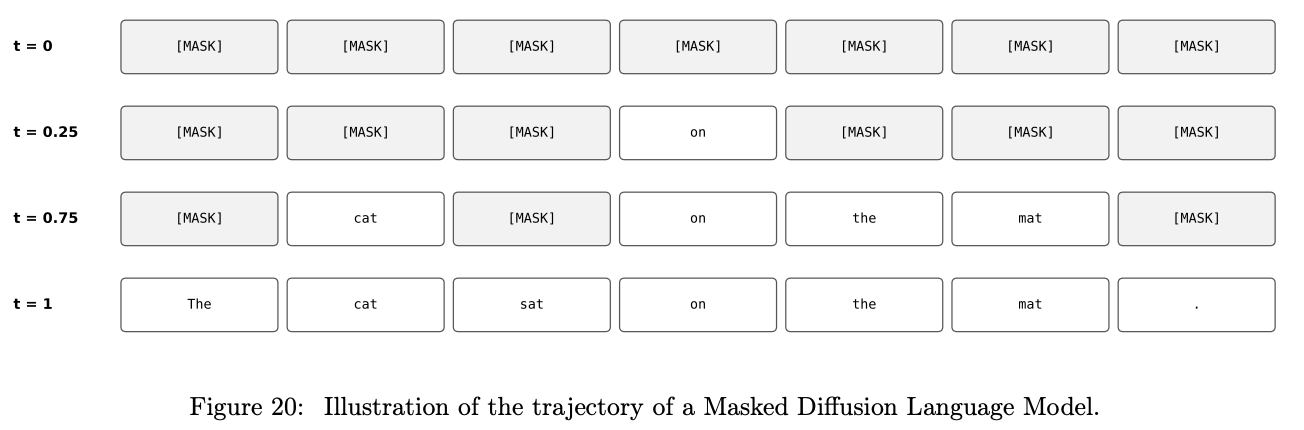
Example 39 (Masked Diffusion Language Model). A specific case of the above method is masked diffusion language models (MDLMs). The idea of MDLMs is that we can extend the vocabulary of tokens $V = {v_1, \ldots, v_V}$ with a new token $[\text{mask}]$ that indicates that this token is missing (or was masked). Specifically, we set $V = {v_1, \ldots, v_V, [\text{mask}]}$ and the initial point is simply $[\text{mask}]^d$, i.e. the sequence that is all-masked. Formally, this means setting $p_{\text{init}} = \delta_{[\text{mask}]^d}$ in the above framework. The sampling procedure is illustrated in Figure 20.
就是说在初始阶段,我们直接把所有token填充成mask,这样就不会包含任何随机信息了,训练会更简单。
- 终于,终于,我们给出完整的训练伪代码(如下图所示),需要注意的是对t时刻的x进行采样时,我们万万不能直接用${\kappa}_t$对noise和z进行差值采样,因为我们是离散空间,两个点之间根本无法进行差值,所以我们先用$m_j \sim Bernoulli(\kappa_t)$来决定第j个token是noise还是z的第j个token,进行d次得到x。

Discrete Diffusion Models vs Autoregress Models
Advantages
- Generate Multiple Tokens in Parallel -> More Speed ?!
- Generate Tokens in any order -> Text editing ?!
- New probability paths -> Can we design ones that make semantic sense?
Disadvantages
- No KV caching -> Less Speed ?!
- Need to learn how to generate Tokens in any order -> Harder to learn?!
- Autogressive order (left-to-right) makes semantic sense -> Is it worth it ?
So ?
- 在不同场景下,它们各有优势和劣势,至于哪个更好,让field和future决定吧!
结束了吗?
- 至此,本次课程基本结束,后面还有一些补充的证明附录,感兴趣的朋友可以去看一下。本讲内容很多,我们相当于是把前几讲的内容从连续空间应用到了离散空间,很多方法和概念都是一样的,当下SOTA的扩散语言模型使用的就是我们提到的这些内容(使用之前提到过的一些transformer架构)!
- note的最后提出有一个Generator Matching framework, 这个框架基于Markovo processes, 希望能统一flow matching, score matching, discrete model等不同空间和数据类型的生成模型😭
- 本系列笔记到此结束了,如果你觉得有用的话,欢迎分享哦!如果你对笔记内容有任何问题或者想法,欢迎在评论区留言,我们一起讨论!
- 我将在课程大横评_0中对MIT_6.S184_5进行总结和评价,敬请期待!