Instruction Timing
- 在上节课中的表格中,我们看到只有lw指令需要经历完整的五个阶段,大概需要800ps的时间,那么我们的cpu在 1s就可以执行1.25亿条指令了,这个速度是非常快的了,问题是我们能否进一步改进它的性能呢?
- 比如单任务完成时间、单位时间更多任务、续航?
| |

- 在计算机中,功率power不是一个很好的衡量energy的指标,因为某些低功率的cpu可能完成同样的任务需要更长的时间,反而花了更多的energy,所以我们更倾向于用energy来衡量性能。
Iron Law of Processor Performance
- $\frac{Time}{Program} = \frac{Instructions}{Program} \cdot \frac{Cycles}{Instruction} \cdot \frac{Time}{Cycle}$
- 这个公式第一眼看上去没有用到流水线,它是直接按照指令顺序一条一条执行的。
- $\frac{Instructions}{Program}$ : 一个程序需要执行的指令数量,这个和编译器的优化程度有关,以及具体的ISA设计(RISC一般比CISC需要的指令更多)。
- $\frac{Cycles}{Instruction}$ : 平均每条指令需要的周期数,在我们当前的设计中,每一条指令就是一个时钟周期,所以CPI = 1, 这个一般由ISA、processor的微架构设计决定。还有一些特殊指令比如(e.g. strcpy), cpi > 1 ; Superscalar processors, cpi < 1.
- $\frac{Time}{Cycle}$ : 每个周期需要的时间,这个由processor的微架构决定,比如关键路径的长度,还有就是硬件的工艺水平、还有电压(低电压节省能源,但是会降速)等因素决定的。
Energy Efficiency
- 如今的处理器已经不再追求单纯的性能了,因为功耗会蹭蹭往上涨,这对于日常使用是不可以接受的,所以我们开始追求在功耗限制下的性能提升。
- 问题来了,在处理器的设计中,能量跑到哪里去了呢?主要是两部分。
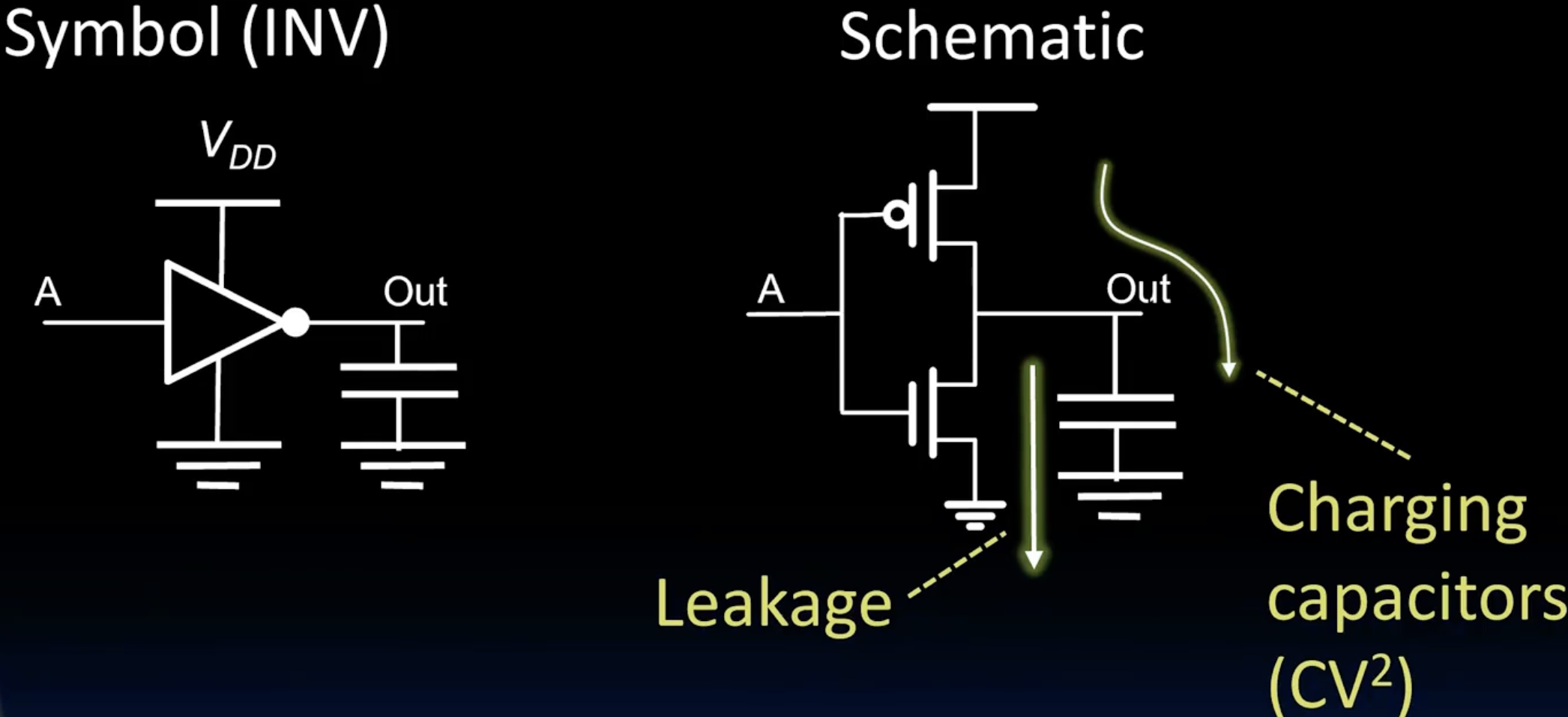
- 在上图中我们看到一个简单的反相器,能量消耗一部分是充放电的消耗,一部分是漏电。 对于充放电消耗,我们都知道电容上储存的能量是$E = \frac{1}{2}CV^2$, 而电源做功是$W = CV^2$, 其中 C是电容,V是电压。那么消耗的能量就是$E = \frac{1}{2}CV^2$, 这个能量消耗一般是电阻放热,电磁波等形式。 这个公式的推导我们可以直接在理想电路中积分得到😉 另一部分是由于晶体管漏电流导致。 总体来说,前者占70%,后者占30%。
- $\frac{Energy}{Program} = \frac{Instructions}{Program} \cdot \frac{Energy}{Instruction}$, 这个公式简化了电路的功耗分析,对于无能的硬件工程师,前者已经超出了能力范围,毕竟编译器优化和ISA设计。。。但是后者是可以优化的,有下面一个等价公式。
- $\frac{Energy}{Program} = \frac{Instructions}{Program} \cdot CV^2$,需要注意的是这里的C指的是所有的单元的等效电容,V是电源电压,电容的优化是工艺水平的事情,电压则需要权衡,电压越低当然功耗越低,但是处理器的频率也会降低。那么如果下一代处理器可以降低15%的电容和电压,那么能量消耗就可以降低接近40%了。
- 当然Denard定律已经不再适用了,因为电压不能在继续降低了,不然漏电会更加严重。同时晶体管也不能继续缩小了,因为工艺水平达到了物理极限,need to go to 3D。
- $Performance (Tasks/Second) = Power (Joules/Second) \cdot 能效 (Tasks/Joule)$,在指定功率的情况下,如何提高单位能量完成的任务,是提高如今能量瓶颈下性能的关键。
Pipelining RISC-V
- 事实上,我们之前设计的单周期处理器没有人会用,和洗衣服道理一样,每一个指令都要完整的经历5个阶段(可能少于5个),下一个指令才能开始执行,这无疑是非常低效的。
- 我们可以在每个阶段都执行不同的指令,然后使用寄存器来分隔不同的阶段,总体来说,由于时钟周期受制于最长的阶段,所以单个指令的完成时间会增加,但是总的吞吐量会大大增加。
| Single Cycle | Pipelined | |
|---|---|---|
| Timing | $t_{step} = 100\cdots 200\quad ps$ | $t_{cycle} = 200\quad ps$ |
| Register access only 100ps | All cycles same length | |
| Instruction time, t_{instruction} | = t_{cycle} = 800ps | 1000ps |
| CPI (Cycles per Instruction) | ~ 1(ideal) | ~ 1 (ideal), < 1(actual) |
| Clock rate, f_s | 1 / 800 ps = 1.25GHz | 1 / 200ps = 5GHz |
| Relative speed | 1x | 4x |
- 令人意外的是CPI竟然没有增加,看似我们的一条指令现在需要经历5个阶段,并且每一个阶段都要1次时钟周期,但是其实当流水线满载的时候,一个时钟周期就相当于完成了一条指令,所以CPI等效是1,为什么是ideal呢?因为在实际情况中,有一些error,比如数据冒险、访存无效等情况会增加cycle数。
Pipelining Datapath
- 对我们之前的Datapath进行改造:
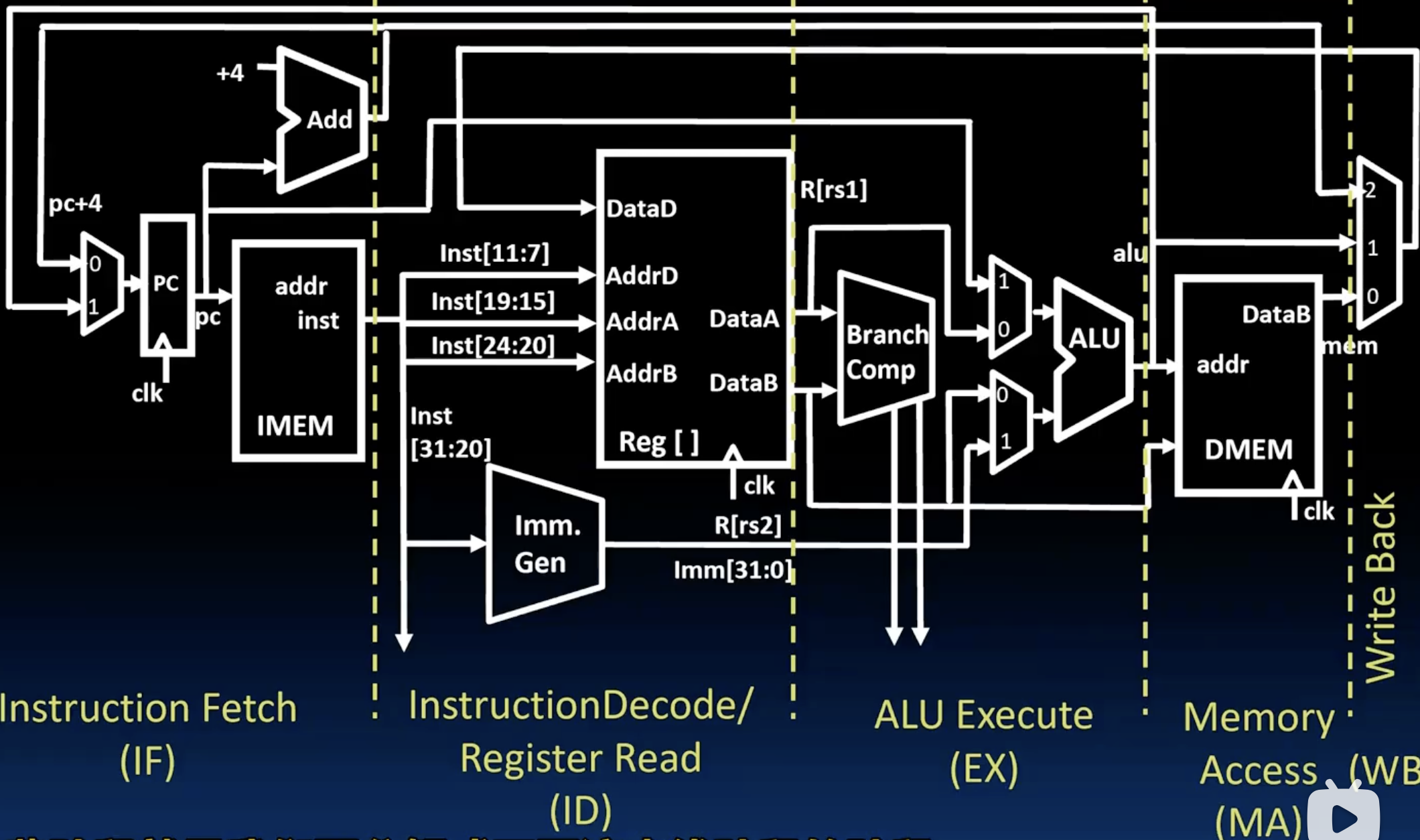
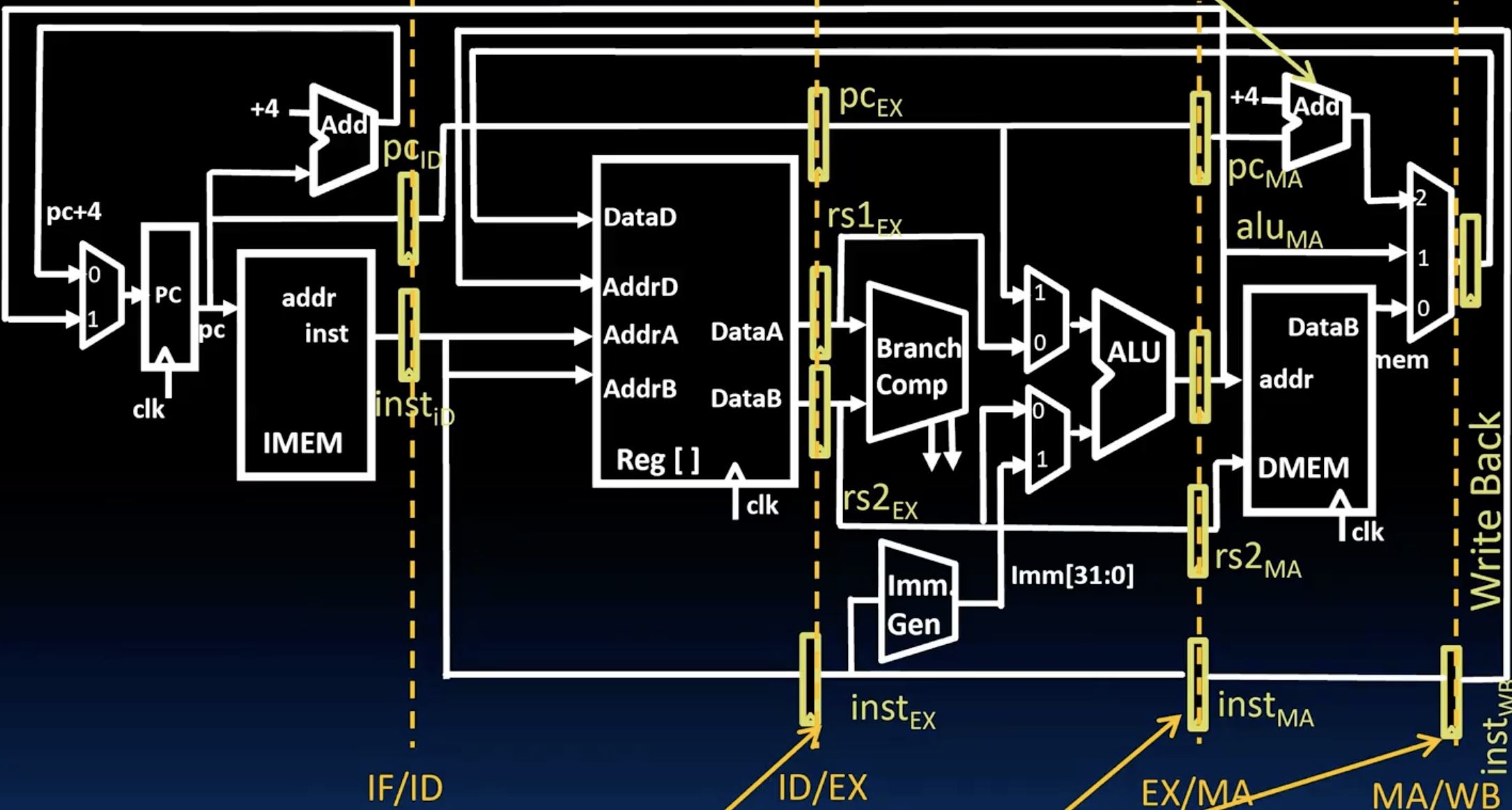
- 对比前后两张图,我们可以明显的发现后者多了很多中间寄存器,为了保证我们的不同指令可以在不同的阶段执行,我们必须将它们的instruction,pc, control signal, data等分开存储,每次时钟一上升,就将这些寄存器的值传递到下一个阶段的寄存器中去,这样就保证了每个阶段都在处理不同的指令了。
- 同时我们注意到在writeback阶段,应该是有一个pc+4的选择的,但是这里并没有仿照别的数据一样用3个寄存器来分别存储,而是直接在mem阶段加了一个固定的+4加法器,为什么呢?因为这样的成本要低于添加三个中间pc+4的寄存器。
- 同时,Control signal也是一样的道理,每一个寄存器(用来存储pc)的都会更宽一些,因为它要存储这些control signal,并且由于需要的信号是随着阶段的增加而减少,所以此类寄存器的宽度也是逐渐减少的。
Pipeline Hazards
- 由于我们的处理器现在同时执行多条指令,所以它们之间可能出现一些问题,主要分为三种:
- Structural hazard :
- A required resource is busy(e.g. needed in multiple stages)
- Data hazard :
- Data dependency between instructions
- Need to wait for previous instruction to be complete its data read/write
- Control hazard :
- Flow of execution depends on previous instruction
- Structural hazard :
Structural Hazard
- Problem: Two or more instructions in the pipeline compute for access to a single physical resource.
- 比如说在我们之前的datapath设计中,为什么我们一定要加一个固定的pc+4加法器,如果没有的话,那么它将会占用ALU的资源,而ALU几乎每一个指令都要用到,那么流水线只能等一轮才能空出ALU,这就是一个structural hazard。
- Solution 1: Instructions take it in turns to use resource, some instructions have to stall.
- Solution 2: Add more hardware to machine.这个就是我们处理pc+4加法器的方法了,增加硬件资源总能解决structural hazard的问题。
- Regfile Structural Hazard : 为什么我们的寄存器文件需要设计成两个读口一个写口呢?因为每一个指令在decode阶段最多读两个寄存器,在writeback阶段最多写一个寄存器,所以这样设计保证了任何指令任何阶段都不会出现structural hazard。
- Memory Structural Hazard : 这里我不得不夸一夸这个课实在是讲的太好了,连起来了,都连起来了🥹,记得之前我们说过的奇怪的IMEM和DMEM吗?现在我们可以结合Structural Hazard来理解,在同一个stage,可能有两个指令,一个在fetch阶段,一个在mem阶段,如果它们共用一个memory(主内存),那么就会出现structural hazard,所以我们设计了两个位于处理器上的小cache,一个是IMEM,一个是DMEM,这样就不用争夺主内存了。
- 总而言之,通过增加硬件资源(ISA),我们可以轻松解决structural hazard的问题。
Data Hazard
- Register Access:
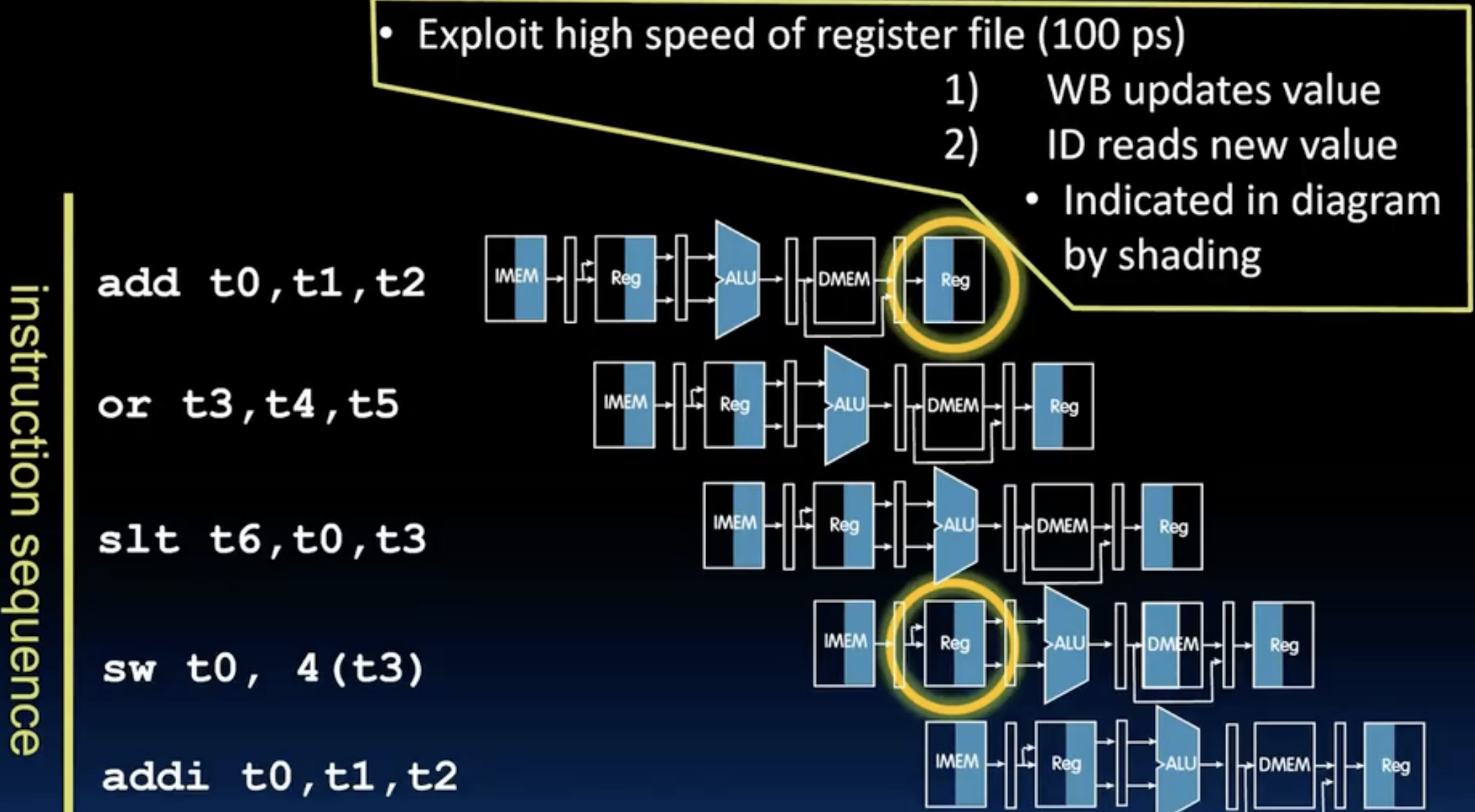
- 在上图中,我们发现在光圈时刻,add指令要写回t0寄存器,sw指令要读取t0寄存器,这就是一个data hazard,如何解决呢?这个通常和我们的register file设计有关,一般来说,我们的寄存器文件是高速的,比如一个cycle是200ps,它的读取和写入只要100ps,那么它就是一个单周期读写寄存器,首先WB update value,然后ID read new value,这样就解决了这个问题,但是有的同学就要问了,这个是cycle较长的情况,如果是超级高频的处理器,一个时钟周期不足以完成读和写,那么。。。(在这里我们不讨论)
- ALU Result:
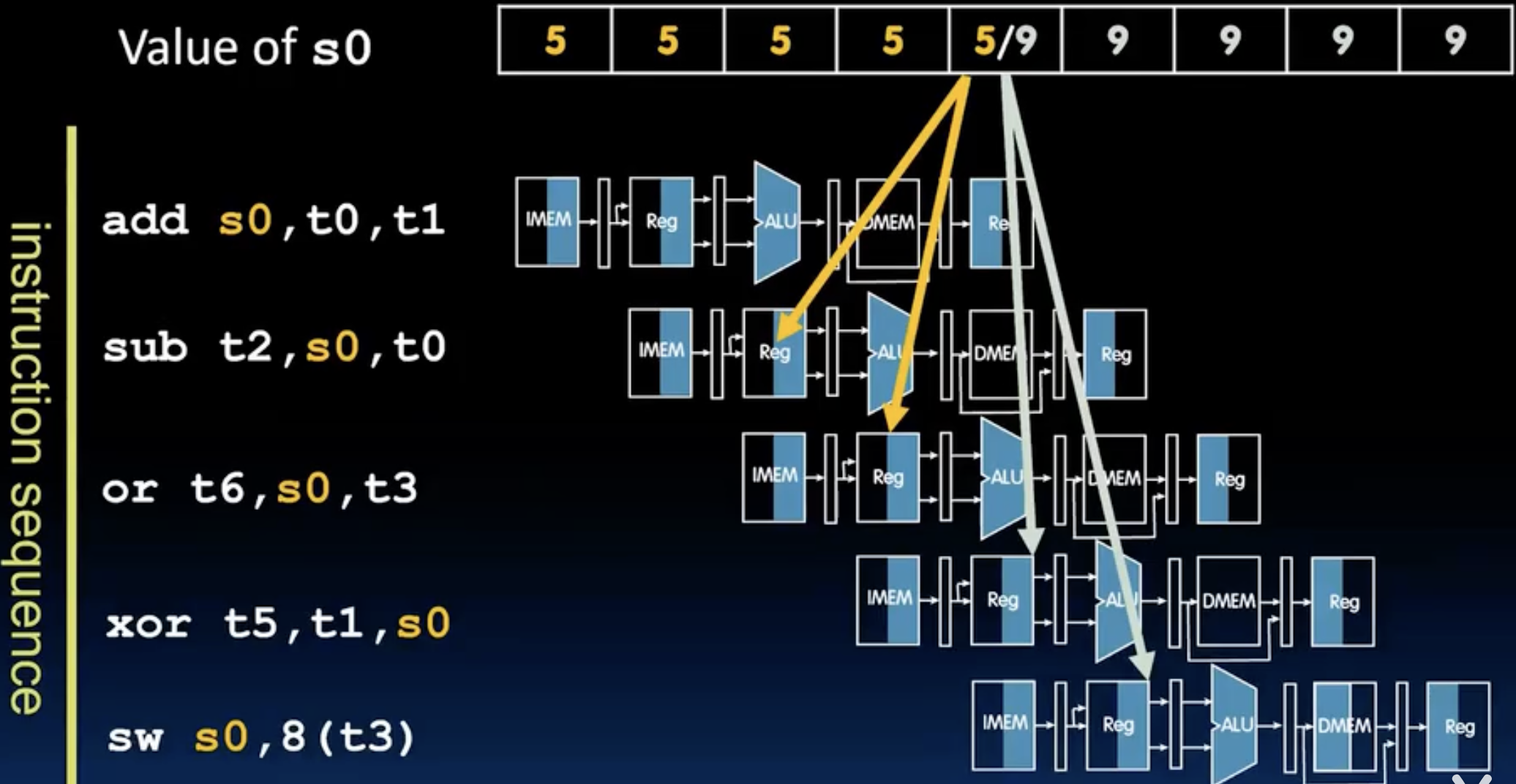
可能有人有疑问,为什么上图中的writeback阶段的s0是5/9呢?之前说过常规的寄存器文件是half-to-half的,所以需要一半的cycle才能写入。
在上图中,我们发现除了第一个指令s0是dest,别的指令s0都是src,那么在第一个指令更新完s0之前,后面的指令都进行不下去了,这就是一个data hazard, 如何解决呢?
- Solution 1: Stalling
- 显然stalling会降低流水线的性能,但是为了保证程序的正确性,不得已而为之。实际的编译器会重新安排代码顺序将一些不依赖s0的指令放在s0之后,来缓解这个损失,如果实在找不到合适的指令,那么在RISC-V中默认的就是nops:addi x0, x0, 0 来站位。
- Solution 2: Forwarding (aka Bypassing)
- Don’t wait for it to be stored in a register
- Requires extra connections in the datapath
- 梦回ICS流水线:我们需要在ALU的输入增加两个mux选择,一个是当inst_EX.rd = inst_ID.rs1时,直接将ALU的输出forward到ALU的输入;另一个是当inst_MEM.rd = inst_ID.rs1时,直接将MEM阶段的结果forward到ALU的输入,如果再往后推一个阶段的话,由于寄存器文件的half-to-half设计,直接就解决了。
- Solution 1: Stalling
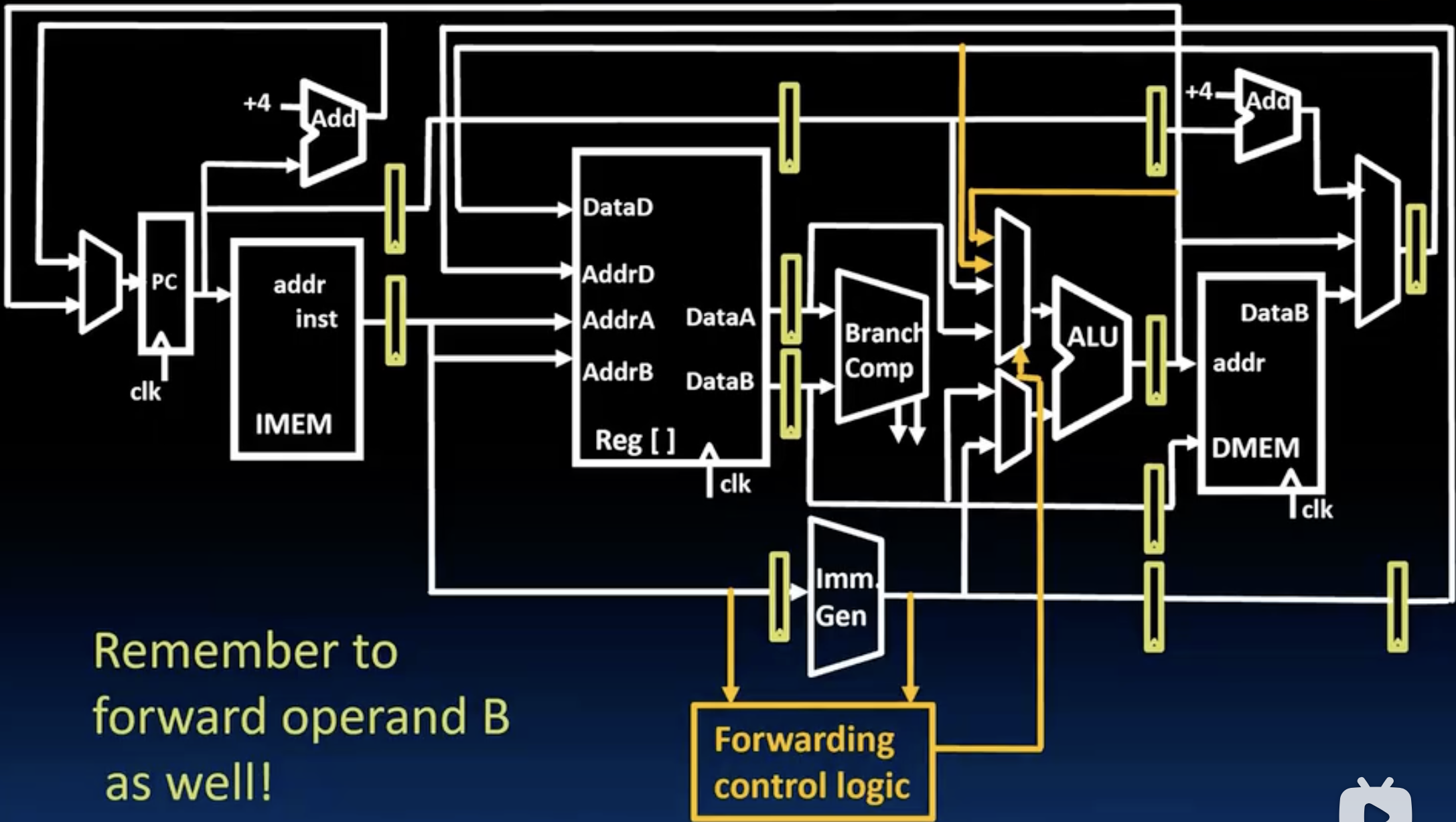
- 上图是datapath的forwarding设计,除了在ALU和MEM的输出增加了forwarding连到了ALU的输入mux之外,还需要为mux添加一个forwarding control logic来判断什么时候选择那两个家伙,而这个control signal的生成又依赖于decoder和alu阶段指令,所以可以看到control logic的输入是inst_ID和inst_EX,此外应该还有inst_MEM啊,对此我觉得是图中没有画出来。
- 同时,别忘了对ALU的另一个输入operand B也要进行forwarding的设计,原理是一样的。
Load Data Hazard
- 之前提到的data hazard可以利用forwarding来解决,但是当指令是load时,事情就变得麻烦了。
| |
- 在上面的例子中,第一条指令的load只有在mem阶段的输出才得到s2,但是当mem结束时,第二条指令的alu阶段也结束了,所以根本来不及forwarding了,第三条指令是来得及的。
- 这种情况下我们需要stall,来延迟这个and的执行。那么问题来了,如何将and s4,s2,s5指令stall呢, 在add指令取指之后,此时应该可以检测到它和lw的数据冲突了,直接将和新状态的写入相关的信号设为禁用,这样pc就不会更新,下一条指令仍然是add s4,s2,s5, 这样就完成了stall了。
| |
- 在做完一个周期的流水线暂停之后,add指令的alu阶段可以接受lw指令的mem阶段的forwarding了,这样就解决了这个load data hazard的问题了。
- 在编译器层面,我们当然可以直接插入一个nop指令来延迟,但是这样会导致代码臃肿和性能下降,所以现代编译器会自动安排指令顺序,找到一些不依赖lw的指令来延迟。
| |
Control Hazard
| |
- 两次延迟的代价还是太高了,如何减少呢?我们采用和load一样的方法,在beq的alu阶段检测到需要跳转,那么直接将后面两条指令变成nop,注意这里我们不需要限制pc到更新,因为需要立刻跳转到label1.
- 所以如果分支taken了,那么我们将要stall两次,如果分支not taken了,那么就不需要stall了,这样就减少了不必要的stall了。
- 当然,现代处理器采用了分支预测器来预测分支的结果,最简单的一种是1位分支预测器,记录上一次的分支结果,如果上一次是taken,那么下一次预测就是taken,如果上一次是not taken,那么下一次预测就是not taken,当然还有更复杂的分支预测器,能达到90%的预测准确率,在使用分支预测的时候,我们直接根据预测结果来选择beq的下一条指令,在过了两个阶段后,我们可以check guess是否正确,如果正确就继续执行,如果不正确就将错误的指令变成nop,并且跳转到正确的地址。
| |
Superscalar Processors
- 5阶段流水线是当今80~90%处理器的首选方案,但是性能仍然可以进一步提高,比如设计10阶段流水线。。。这样当然能大大提高时钟频率,但是也容易造成更多的hazard,解决起来也更麻烦,一般来说CPI都会大于1.
- 于是出现了Superscalar Processors, 它的原理是使用了多个并行的流水线来同时执行多条指令,比如一个4GHz 4-way multiple-issue的处理器,每秒钟可以执行16B条指令,peak CPI = 0.25, peak IPC = 4, 但是实际的IPC肯定小于4,因为有hazard的存在。
- 它使用了out-of-order execution来解决hazard的问题,在它的多个流水线中,有int、float、load/store等不同类型,每条指令会根据它的类型被分配到不同的流水线中去执行,并且乱序执行(检测依赖关系),最后再根据指令的顺序commit结果。